
Software overview
RepeatModeler is a repeat-identifying software that can provide a list of repeat family sequences to mask repeats in a genome with RepeatMasker.
Things to consider with this software is that it can take a long time with large genomes (>1GB requires 96hrs on a 16 CPU node). You also need to set the correct parameters in RepeatModeler so that you get repeats that are not only grouped by family but are also annotated (learn more in the section Repeats identification).
Consider browsing the software resources to get the most up-to-date news. You can use the links provided anytime to explore in-depth documentation or get guidance for results interpretation.
- Project Page [services, software, docs, community]: http://www.repeatmasker.org/ ⤴
- RepeatModeler [download, installation, example run]: http://www.repeatmasker.org/RepeatModeler/ ⤴
- RepeatMasker [download, installation]: http://www.repeatmasker.org/RepeatMasker/ ⤴
Single Use - online service
There is a RepeatMasker Web Server ⤴ available online. Just go there, paste your query DNA sequence (or load it from a file), and set up the analysis variant using options widgets. The web server combines functions of both RepeatModeler and RepeatMasker.

| PROS: | CONS: |
|---|---|
| • installation NOT required | • queue system with limited resources |
| • straightforward interface and usage | • only Dfam database available as the reference |
| • easily accessible option description with usage tips | • limited possibility of multiple tasks automation |
| • two separate sections for basic and advanced options | • manual submission of every task |
| • on request e-mail notification or HTML report |
Regular Use - get it locally
If you suppose more regular analyses that require repetition detection or the subject of your research are large genomes, you should consider installing the Repeat-* packages locally, especially on the HPC (High-Performance Computing) infrastructure.
There are several ways to get the RepeatModeler and RepeatMasker installed on your computing machine:
- install both with Conda (it also installs all prerequisites):
conda install -c bioconda repeatmodeler(installs version=1.0.8 in 2022)conda install -c "bioconda/label/main" repeatmodeler=2(installs version=2.0.3 in 2022)- browse other versions at https://anaconda.org/bioconda/repeatmodeler/files ⤴
- run using containers (see detailed instructions ⤴):
- docker:
docker run -it --rm dfam/tetools:latest - singularity:
singularity pull dfam-tetools-latest.sif docker://dfam/tetools:latest
and thensingularity run dfam-tetools-latest.sif - wrapper:
curl -sSLO https://github.com/Dfam-consortium/TETools/raw/master/dfam-tetools.sh
and then. ./dfam-tetools.sh
- docker:
- download source distribution:
- RepeatModeler-2.0.3.tar.gz ⤴ (latest release in 2022)
wget http://www.repeatmasker.org/RepeatModeler/RepeatModeler-2.0.3.tar.gz - browse other versions at http://www.repeatmasker.org/RepeatModeler/#source-distribution-installation ⤴
- RepeatMasker-4.1.4.tar.gz ⤴ (latest release in 2022)
wget http://www.repeatmasker.org/RepeatMasker/RepeatMasker-4.1.4.tar.gz - browse other versions at http://www.repeatmasker.org/RepeatMasker/ ⤴
- RepeatModeler-2.0.3.tar.gz ⤴ (latest release in 2022)
- download the GitHub development source code from https://github.com/Dfam-consortium ⤴:
Among those, the installation within the Conda environment seems the most straightforward, hassle-free, and robust. This one is also universally good, regardless of using a local machine or remote HPC infrastructure.
Install with Conda (once)
Conda ⤴ is an environment management system that runs on all: Windows, macOS, and Linux. Using simple conda-based commands you can create a virtual environment and within it install all required dependencies for a specific pipeline or analytic workflow.
If you are not already using Conda, go to the Basic Developer Libraries ⤴ tutorial (in Data Science Workbook ⤴) for a step-by-step guide on how to set up the environment manager on your target computing machine.
If you have a Mac with a dual processor (Arm64 and Intel’s x86-64) you can find dedicated setup instructions in section Install Basic Developer Tools ⤴ of the Installations on MacBook Pro ⤴ tutorial.
Typically on HPC infrastructure, Conda is pre-installed and available for loading as a module.
At this step, we assume that you have Conda installed on your computing machine/HPC infrastructure.
A. Check Conda version on your local machine
1
conda --version
example output: conda 4.14.0
B. Check available Conda modules on HPC
1
module avail conda
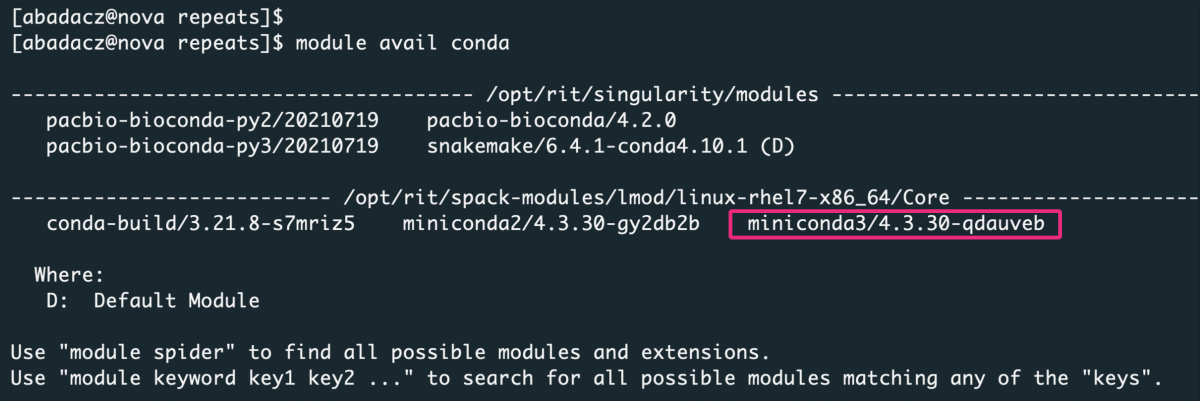
Select conda or miniconda version (from available on your HPC infrastructure) and load it as a module:
1
module load miniconda3/4.3.30-qdauveb
Create new environment
(only once)
If you are following this tutorial for the first time (on a given computing machine), create a new Conda environment in which you install software to identify repeats in the genome.
1
conda create -n repeatmodeler
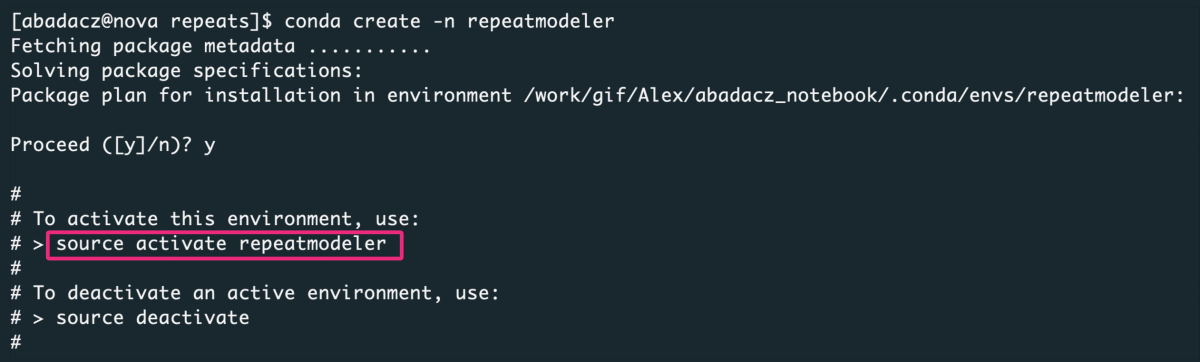
Activate a newly created virtual environment:
1
source activate repeatmodeler

Go to https://anaconda.org/bioconda/repeatmodeler to find the most recent instructions for installing repeatmodeler with conda:
1
conda install -c bioconda repeatmodeler
This step may take several minutes because not only the is
RepeatModeler being installed but also all its dependencies. Once the installation is complete, you can use the conda list command to display all installed libraries and the details of their version and source.
Expand list of installed libraries...
packages in environment at ~/.conda/envs/repeatmodeler: _libgcc_mutex 0.1 main _openmp_mutex 5.1 1_gnu blas 1.0 mkl blast 2.5.0 hc0b0e79_3 bioconda boost 1.57.0 4 bzip2 1.0.8 h7b6447c_0 ca-certificates 2022.10.11 h06a4308_0 certifi 2022.9.24 pip certifi 2022.9.24 py310h06a4308_0 h5py 3.7.0 pip h5py 3.7.0 py310he06866b_0 hdf5 1.10.6 h3ffc7dd_1 hmmer 3.3.2 h87f3376_2 bioconda icu 68.1 h2531618_0 intel-openmp 2021.4.0 h06a4308_3561 ld_impl_linux-64 2.38 h1181459_1 libffi 3.3 he6710b0_2 libgcc-ng 11.2.0 h1234567_1 libgfortran-ng 11.2.0 h00389a5_1 libgfortran5 11.2.0 h1234567_1 libgomp 11.2.0 h1234567_1 libnsl 2.0.0 h5eee18b_0 libstdcxx-ng 11.2.0 h1234567_1 libuuid 1.0.3 h7f8727e_2 mkl 2021.4.0 h06a4308_640 mkl-fft 1.3.1 pip mkl-random 1.2.2 pip mkl-service 2.4.0 pip mkl-service 2.4.0 py310h7f8727e_0 mkl_fft 1.3.1 py310hd6ae3a3_0 mkl_random 1.2.2 py310h00e6091_0 ncurses 6.3 h5eee18b_3 numpy 1.23.3 pip numpy 1.23.3 py310hd5efca6_1 numpy-base 1.23.3 py310h8e6c178_1 openssl 1.1.1s h7f8727e_0 perl 5.32.1 0_h5eee18b_perl5 perl-threaded 5.32.1 hdfd78af_1 bioconda pip 22.2.2 pip pip 22.2.2 py310h06a4308_0 python 3.10.6 haa1d7c7_1 readline 8.2 h5eee18b_0 recon 1.08 hec16e2b_4 bioconda repeatmasker 4.1.2.p1 pl5321hdfd78af_1 bioconda repeatmodeler 1.0.8 0 bioconda repeatscout 1.0.5 h516909a_2 bioconda rmblast 2.2.28 h21aa3a5_4 bioconda setuptools 65.5.0 py310h06a4308_0 setuptools 65.5.0 pip six 1.16.0 pyhd3eb1b0_1 sqlite 3.39.3 h5082296_0 tk 8.6.12 h1ccaba5_0 trf 4.09.1 hec16e2b_2 bioconda tzdata 2022f h04d1e81_0 wheel 0.37.1 pyhd3eb1b0_0 xz 5.2.6 h5eee18b_0 zlib 1.2.13 h5eee18b_0
Type Repeat and press tab to display available programs:

There is also: BuildDatabase available.
Call any program by its name:
BuildDatabase, RepeatModeler, RepeatMasker, RepeatClassifier, RepeatProteinMask, RepeatScout
followed by the -h flag to display the help message or the -version flag to return the current version in use.
1
RepeatModeler -version
OUTPUT: RepeatModeler version 1.0.8
If you have realized already that there is a newer release available and wonder how to get it from the command line, follow the instructions in the next section, Upgrade RepeatModeler.
Upgrade RepeatModeler (optional)
In my case, the default conda install -c bioconda repeatmodeler installation recipe resulted in getting the RepeatModeler in version 1.0.8 instead of the latest release 2.0.3, which provides many more options, such as LTR structural discovery pipeline (-LTRStruct). Thus, let’s upgrade it following scenario A or B!
A. Select from Conda labels
Add the conda-forge channel first to increase the chance of finding all the required dependencies:
1
conda config --add channels conda-forge
Then try to install using the selected label (here: main) and software version (here: 2).
1
conda install -c "bioconda/label/main" repeatmodeler=2
Now, let’s confirm we have upgraded the version of RepeatModeler already:
1
RepeatModeler -version
OUTPUT: RepeatModeler version 2.0.3
This approach is more robust compared to provided below B. Select from Conda files because all dependencies required by the upgraded RepeatModeler are found and installed automatically.
B. Select from Conda files
Note that upgrading the software using a downloaded file may disrupt the other dependencies in your Conda environment. Then you will need to manually find and fix them (e.g., install the required version). However, it is useful when you need a very specific release (e.g., to repeat the analysis with the same settings).
Go to the Files tab at https://anaconda.org/bioconda/repeatmodeler/files (in a web browser) and select desired downloadable file, here repeatmodeler-2.0.3 variant. Using right-mouse, click Copy Link and return to your terminal window.
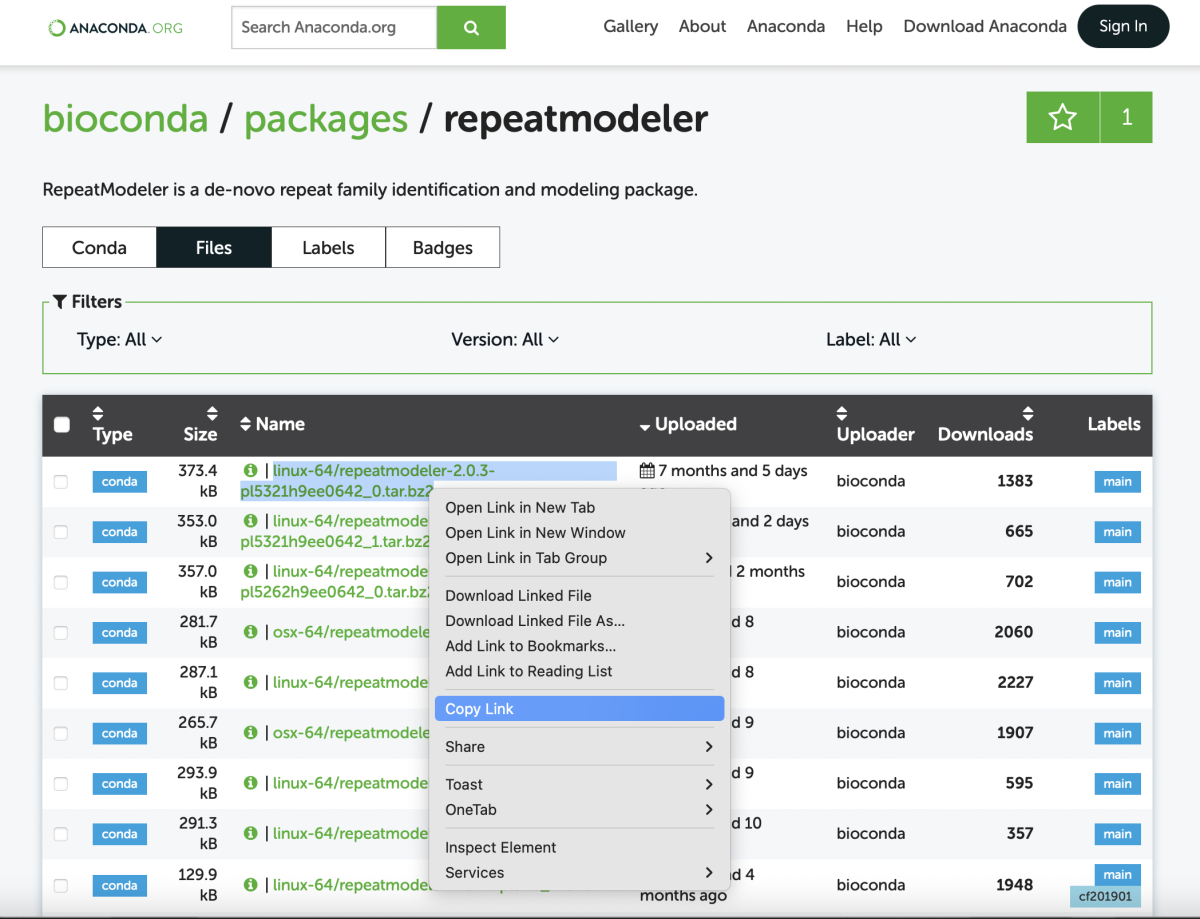
In the command line, use wget followed by a pasted link to download the file.
1
wget https://anaconda.org/bioconda/repeatmodeler/2.0.3/download/linux-64/repeatmodeler-2.0.3-pl5321h9ee0642_0.tar.bz2
You can download this file to any location in the file system on the desired computing machine (including remote HPC infrastructure). It is a temporary file used for the installation step only. So, feel free to download it to the TMP folder, which you clean regularly. Otherwise, if you prefer to keep the installation file for future reference, first create the SOURCE_FILES directory on your /work/user path and (eventually) symlink it to your home. In the future, download all the installation source files to this location to keep a neat organization.
The downloaded file should look something like that:
repeatmodeler-2.0.3-pl5321h9ee0642_0.tar.bz2
Further, you can use it as a source file for the conda install command:
1
conda install repeatmodeler-2.0.3-pl5321h9ee0642_0.tar.bz2
Note that it is a good practice to provide the full path to your source file, in particular, if you use it from an external location in the file system:
conda install /absolute/path/to/source_fileAlso, to install new dependencies within the Conda environment, you first need to
load module {conda_variant} and source activate {conda_env}. You can display all the available Conda environments using the
conda info -e command.
Upgrade blast+ (optional)
The newer BuildDatabase coming with RepeatMasker-2.0.3 uses the -blastdb_version version option of the makeblastdb program in the blast+ package. This option was introduced with the 2.10.0 release. So, to prevent the Unknown argument: “blastdb_version” error, first check your installed version of blast using the conda list command or makeblastdb -version or display available options with makeblastdb -h. If you do not see the -blastdb_version among the options, or the version is older than 2.10, or you simply want to use the latest release, upgrade the blast+ package to 2.10 or newer (check availability at https://anaconda.org/bioconda/blast ⤴):
1
conda install -c bioconda blast=2.12
Now, let’s confirm we have upgraded the version of blast+ already:
1
makeblastdb -version
OUTPUT: makeblastdb: 2.12.0+
Repeats identification pipeline
0. Get your genome ready
The only input required to start the repeats identification is a genome, i.e., the set of DNA sequences provided in one-letter notation (A,T,C,G) compliant with the FASTA format (learn more in the Bioinformatics File Formats ⤴ tutorial). The most common (and acceptable by a program) file extensions include: .fa, .fasta, .fast, .FA, .FASTA, .FAST, .dna, and .DNA.
The excerpt from an example.fasta file:
1
2
3
4
5
6
7
8
>sequence_1
ATGACAACGTCAAATCCTATATTTGTTTAATGAAACAGGTTTAAAGCAATCAGAACTTTACGATCATTATTAAAAAAAAT
ACAGCATGTTTATATATGTGTGTCACCCTCTCACGTCAAATATATAAATGTATAAAAATGTTTTAATATAGTTAAAATTG
...
>sequence_2
GAATTCACTGCTTTATGGGAAACAAAATCTGTCAATTTAGCTATTTTGAATTTAGTCCATATGTACATCCTAGGTTCTTA
AGAATTAATTCATGTTTTAAGATATGTATGAAGTATTAAATAGTTAAATAGATGTTCTTAATAATTGAATACCTTTCCAT
...
Resources of genome data
A. Custom genome data
If you have your preferred genome data to detect repeats within, note that “RepeatModeler is designed to run on assemblies rather than genome reads” and “should be run on a single machine per-assembly”. Please also familiarize yourself with other caveats listed by developers at http://www.repeatmasker.org/RepeatModeler/#caveats ⤴.
B. Genome from public repository
If you do NOT have any genome data, there are several publicly available resources to explore:
- EMBL-EBI: Searching ENA ⤴
- various organism-dedicated web platforms, such as Arabidopsis Information Resource (TAIR) ⤴ for the model higher plant Arabidopsis thaliana ⤴.
Let’s use the Arabidopsis thaliana genome from the TAIR10 release as an example of DNA data in which the RepeatModeler will detect various families of repeats.
1
wget https://www.arabidopsis.org/download_files/Genes/TAIR10_genome_release/TAIR10_chromosome_files/TAIR10_chr_all.fas.gz
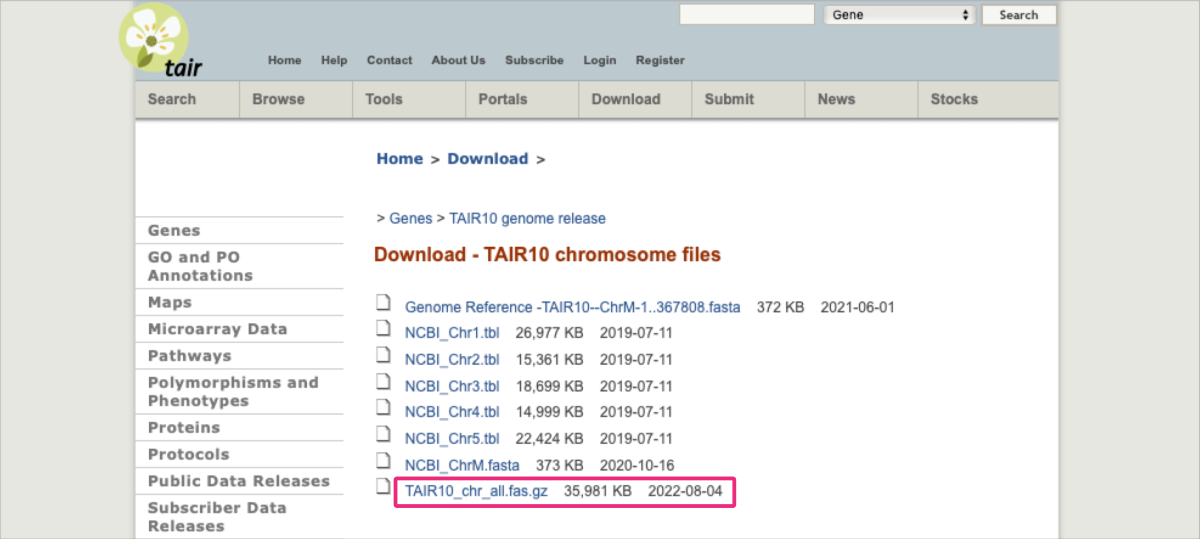
In case the link provided is obsolete, please follow the instructions provided below to find the correct file in the downloadable resource:
1. Go to https://www.arabidopsis.org/download/ ⤴
2. Click on the Genes link.
3. Among folders, find & click the TAIR10 genome release.
4. Among folders, find and click the AIR10 chromosome files.
5. Once you see the page from the screenshot above, apply right-mouse-click on the TAIR10_chr_all.fas.gz file and select Copy Link from the pop-up menu.
6. Go to the terminal and use the
wget command followed by a copy-pasted link.
Note that the downloaded file is compressed (.gz) and the BuildDatabase program is unable to process such files. You can extract the file using the gunzip command with the -d flag:
1
gunzip -d TAIR10_chr_all.fas.gz
1. Build Database
This is basically a wrapper around AB-Blast’s and NCBI Blast’s DB formatting programs. It assists in aggregating files for processing into a single database.
source: program’s help message
The BuildDatabase step is quick (several seconds at most).
Usage syntax:
1
2
3
4
BuildDatabase -name {database_name} {genome_file-in_fasta_format}
e.g.,
BuildDatabase -name arabidopsis TAIR10_chr_all.fas
Preview options using BuildDatabase -h
BuildDatabase [-options] -name "mydb.fasta"
-name {database name}
The name of the database to create.
-engine {engine name}
The name of the search engine we are using. I.e abblast/wublast or
ncbi (rmblast version).
-dir {directory}
The name of a directory containing fasta files to be processed. The
files are recognized by their suffix. Only *.fa and *.fasta files
are processed.
-batch {file}
The name of a file which contains the names of fasta files to
process. The files names are listed one per line and should be fully
qualified.
2. Repeat Modeler
RepeatModeler is a de novo transposable element (TE) family identification and modeling package.
source: program’s documentation
The RepeatModeler step can take longer than 96 hours on one node with 16 threads if the genome is larger than 1GB.
Usage syntax:
1
2
3
4
RepeatModeler -database {database_name} -pa {number of cores} -LTRStruct > out.log
e.g.,
RepeatModeler -database arabidopsis -pa 36 -LTRStruct > out.log
Preview options using RepeatModeler -h
RepeatModeler [-options] -database {XDF Database}
-database
The prefix name of a XDF formatted sequence database containing the
genomic sequence to use when building repeat models. The database
may be created with the WUBlast "xdformat" utility or with the
RepeatModeler wrapper script "BuildXDFDatabase".
-engine {abblast|wublast|ncbi}
The name of the search engine we are using. I.e abblast/wublast or
ncbi (rmblast version).
-pa #
Specify the number of shared-memory processors available to this
program. RepeatModeler will use the processors to run BLAST searches
in parallel. i.e on a machine with 10 cores one might use 1 core for
the script and 9 cores for the BLAST searches by running with "-pa
9".
-recoverDir {Previous Output Directory}
If a run fails in the middle of processing, it may be possible
recover some results and continue where the previous run left off.
Simply supply the output directory where the results of the failed
run were saved and the program will attempt to recover and continue
the run.
3. Repeat Masker
RepeatMasker screens DNA sequences for interspersed repeats and low complexity DNA sequences. All recognized transposons are masked. In the masked areas, each base is replaced with an N, so that the returned sequence is of the same length as the original. Default settings are for masking all type of repeats in a primate sequence.
source: program’s documentation
The RepeatMasker step can take about 24-48 hours to finish on a genome over 1GB.
Usage syntax:
1
2
3
4
RepeatMasker -pa 36 -gff -lib {consensi_classified} -dir {dir_name} {genome_in_fasta}
e.g.,
RepeatMasker -pa 36 -gff -lib consensi.fa.classified -dir MaskerOutput TAIR10_chr_all.fas
Use the RepeatMasker -h command to display a full list of options.
Create SLURM script
The complete analysis for the 1GB genome may exceed a hundred hours on one node with 16 threads. That is today’s upper limit of laptop capacity. Thus, having access to the HPC infrastructure can definitely increase the efficiency of your analysis. That requires preparing a script that informs the queuing system of the requirements for a given computational task.
If you are not familiar with the Job Scheduling and types of Workload Managers, please start with tutorials present in Data Science Workbook ⤴:
- Introduction to SLURM: Simple Linux Utility for Resource Management ⤴
- Creating SLURM Job Submission Scripts ⤴
- Tutorial: Submitting Dependency Jobs using SLURM ⤴
Create an empty script file, e.g., touch repeats_detection.sh, and edit it in the favorite text editor. Then copy-paste the template script provided below. Remember to update the filenames of your inputs and adjust the options of the programs (if needed).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=36
#SBATCH --time=100:00:00
#SBATCH --output=slurm-%j.out
###-LOAD PRE-INSTALLED MODULES
module load miniconda3/4.3.30-qdauveb
###-LOAD SELECTED CONDA ENVIRONMENT # custom, requires prior creation by a user
source activate repeatmodeler
###-UPDATE YOUR INPUTS
INPUT=TAIR10_chr_all.fas # provide filename of the genome in FASTA format
DB=Arabidopsis # make up a customized name for your database
###-SETUP DETECTION OF REPEATS
#echo "Build database ..."
#time BuildDatabase -name $DB $INPUT
echo "Run RepeatModeler ..."
time RepeatModeler -database $DB -pa 36
ln -s RM_*/consensi.fa.classified ./
echo "Run RepeatMasker ..."
time RepeatMasker -pa 36 -gff -lib consensi.fa.classified $INPUT
Submit the script in the queueing system:
1
sbatch repeats_detection.sh
Check status of your job in the queue:
1
squeue -u {your_username}
Once the calculations start, the ` slurm-{JOBID}.out` file will be created in your working directory. You can look into the file to browse the standard output and check if any errors were thrown.
Use the tips provided below in case your analysis crashes with errors.
ERROR 1
Can't locate File/Which.pm in @INC (you may need to install the File::Which module) (@INC contains: ... ) at /work/gif/Alex/abadacz_notebook/.conda/envs/repeat3/bin/filter-stage-1.prl line 14.
Try solutions:
The error results from the perl5 package. You can follow one of the two solutions:
Solution 1:
open the file indicated after "at":nano /work/gif/Alex/abadacz_notebook/.conda/envs/repeat3/bin/filter-stage-1.prl
and comment with # character the line shown:14 #use File::Which qw(which where);
Solution 2:
install/upgrade the missing dependency of perl package:conda install perl-File-Which
Processing times
The table contains the processing times for each step of the repeats identification pipeline for two genomes that differ by order of magnitude in size (~100 MB vs. 1 GB). The calculations were performed on a single node with 36 cores (Nova cluster @ISU HPC ⤴). As you can see, for the 1 GB genome, the complete pipeline requires about 25 hours in the clock when employing 36 cores (real-time). The time summed over the cores used reaches 300 hours (over 12 days). So that’s roughly how much computation would take if only one thread is available.
You can use the data from the table to estimate the resources needed for your analysis. If you have fewer cores available, request a longer wall time. Always add a 10-20% time reserve.
| genome | genome size | bp number | time [real/user] | time [real/user] | time [real/user] | cores |
|---|---|---|---|---|---|---|
| BuildDatabase | RepeatModeler | RepeatMasker | ||||
| Arabidopsis | 116 MB | 120 M | 8s / 1s | 4h23m / 67h | 5m / 1h21m | 36 |
| 9h30m / - | 14m / - | (16) | ||||
| Abalone | 1.1 GB | 1130 M | 22s / 9s | 20h27m / 258h | 2.5h / 30h | 36 |
| ~96h / - | 24-48h / - | (16) |
Results interpretation
Outputs overview
^assuming the database name is Arabidopsis
| BuildDatabase | RepeatModeler | RepeatMasker |
|---|---|---|
| Arabidopsis.DB.nhr | RM_{ID}.{date_stamp} | Arabidopsis.tbl |
| Arabidopsis.DB.nin | - round-{N} | Arabidopsis.masked |
| Arabidopsis.DB.nnd | - consesi.fa | Arabidopsis.out |
| Arabidopsis.DB.nni | - consesi.fa.classified | Arabidopsis.out.gff |
| Arabidopsis.DB.nog | - families.stk | |
| Arabidopsis.DB.nsq | - families-classified.stk | |
| Arabidopsis.DB.translation | - rmod.log |
1. BuildDatabase produces the database files.
2. RepeatModeler returns the consesi.fa.classified required by the RepeatMasker step. The file is located within the automatically created directory with the name starting in “RM_“.
Make sure you softlink the classified file to the RepeatMasker workdir, otherwise you will not get a table of classified elements after the run.
3. RepeatMasker generates the final outputs:
- .tbl - a text file containing the summary table of the detected repeats
- .gff - a General Feature Format file containing information about repeats’ annotations
- .masked - the genome FASTA file with bases of the detected repeats masked by the “N” letter
You can use the data from these files depending on the purpose of your further analysis.
Let’s look into the results obtained for the Arabidopsis…
A. Repeats summary table
The file contains a brief of the detected repeats, providing details of the classified families and some statistics.
Arabidopsis.tbl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
==================================================
file name: TAIR10_chr_all.fas
sequences: 7
total length: 119668634 bp (119483030 bp excl N/X-runs)
GC level: 36.06 %
bases masked: 19074485 bp ( 15.94 %)
==================================================
number of length percentage
elements* occupied of sequence
--------------------------------------------------
SINEs: 0 0 bp 0.00 %
ALUs 0 0 bp 0.00 %
MIRs 0 0 bp 0.00 %
LINEs: 2556 1369351 bp 1.14 %
LINE1 2556 1369351 bp 1.14 %
LINE2 0 0 bp 0.00 %
L3/CR1 0 0 bp 0.00 %
LTR elements: 5178 5977887 bp 5.00 %
ERVL 0 0 bp 0.00 %
ERVL-MaLRs 0 0 bp 0.00 %
ERV_classI 0 0 bp 0.00 %
ERV_classII 0 0 bp 0.00 %
DNA elements: 2921 1940376 bp 1.62 %
hAT-Charlie 0 0 bp 0.00 %
TcMar-Tigger 0 0 bp 0.00 %
Unclassified: 24344 7754373 bp 6.48 %
Total interspersed repeats: 17041987 bp 14.24 %
Small RNA: 0 0 bp 0.00 %
Satellites: 0 0 bp 0.00 %
Simple repeats: 35185 1555134 bp 1.30 %
Low complexity: 9206 507160 bp 0.42 %
==================================================
* most repeats fragmented by insertions or deletions
have been counted as one element
The query species was assumed to be homo
RepeatMasker version open-4.0.6 , default mode
run with rmblastn version 2.11.0+
The query was compared to classified sequences in "consensi.fa.classified"
RepBase Update 20110419-min, RM database version 20110419-min
B. Repeats’ annotations in the GFF file
Now, there is also a GFF that can be used for many other genomic comparisons, e.g., you can use start-end positions of the detected motif to display repeats on the ideogram (see tutorial in the Data Visualization ⤴ section: Visulaize Chromosome Bands using Ideogram ⤴).
Encoding the columns:
- 1 - chromosome id
- 4 - start position of the detected repeat
- 5 - end position of the detected repeat
- 6 - score of the detected repeat (confidence for feature)
- 7 - strand (+,-, .)
- 9 - name/attributes of the detected repeat
Arabidopsis.gff
1
2
3
4
5
6
7
8
9
10
11
12
13
14
##gff-version 2
##date 2022-11-17
##sequence-region TAIR10_chr_all.fas
Chr1 RepeatMasker similarity 1 115 13.1 + . Target "Motif:A-rich" 1 107
Chr1 RepeatMasker similarity 1066 1097 10.0 + . Target "Motif:(C)n" 1 32
Chr1 RepeatMasker similarity 1155 1187 17.1 + . Target "Motif:(TTTCTT)n" 1 33
Chr1 RepeatMasker similarity 3775 3920 25.8 - . Target "Motif:rnd-4_family-633" 434 573
Chr1 RepeatMasker similarity 4291 4328 8.4 + . Target "Motif:(AT)n" 1 38
Chr1 RepeatMasker similarity 5680 5702 9.3 + . Target "Motif:(T)n" 1 23
Chr1 RepeatMasker similarity 8669 8699 0.0 + . Target "Motif:(CT)n" 1 31
Chr1 RepeatMasker similarity 9961 10030 20.7 + . Target "Motif:(AT)n" 1 70
Chr1 RepeatMasker similarity 10814 10885 28.7 + . Target "Motif:(AT)n" 1 71
Chr1 RepeatMasker similarity 11889 11960 12.9 + . Target "Motif:rnd-1_family-191" 48 131
...
^ truncated file for visualization; the complete gff file contains 83285 hits
C. Genome with masked repeats in FASTA file
By default, the RepeatMasker also generates the FASTA file of the input genome, in which all bases of the detected repeats are replaced (masked) with the “N” letter.
Arabidopsis.masked
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>Chr1 CHROMOSOME dumped from ADB: Feb/3/09 16:9; last updated: 2009-02-02
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNGGTTTCTCTGGTTGAAAATCATTGTGTATATAATG
ATAATTTTATCGTTTTTATGTAATTGCTTATTGTTGTGTGTAGATTTTTT
...
CAGAAAGTGGCAACANNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNAAA
TTGAGAAGTCAATTTTATATAATTTAATCAAATAAATAAGTTTATGGTTA
AGAGNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNGAGACATACTGAA
...
TCTTATTCTTAATTAGTTACCATGTCTTGANNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNN
>Chr2 CHROMOSOME dumped from ADB: Feb/3/09 16:10; last updated: 2009-02-02
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
...
^ truncated file for visualization;