Introduction
Single-cell RNA sequencing (scRNA-seq) has enhanced our ability to study cellular heterogeneity during development and differentiation. One prominent use case is examining how human embryonic stem cells (hESCs) differentiate into specific neuronal subtypes, such as midbrain floorplate progenitors.
In this tutorial, we will walk through a practical PiPseq pipeline using a real-world scRNA-seq dataset derived from differentiated hESCs. PiPseq (Pronuclei in Profile sequencing) is a general-purpose pipeline for processing single-nuclei or single-cell RNA-seq data. Specifically, we will focus on how to:
- Pre-process scRNA-seq data
- Perform quality control and filtering
- Cluster cells and visualize them with UMAP
- Highlight expression of developmental marker genes, such as SHH
We will use a publicly available dataset from Tiklova et al. (2019), which characterized midbrain differentiation in hESCs using high-throughput single-cell RNA sequencing. We will analyze sample ERR14876813, which represents day 25 of hESC differentiation into midbrain floorplate progenitors. By day 25, hESCs have undergone substantial differentiation and begin to express key ventral midbrain markers, including SHH, FOXA2, and LMX1A.
This sample is derived from the study:
1
| Tiklova, K. et al. (2019). Single-cell transcriptomics reveals correct developmental dynamics and high-quality midbrain cell types by improved hESC differentiation. Nature Communications. DOI: 10.1038/s41467-019-12666-z
|
| Attribute |
Description |
| Sample Accession |
ERR14876813 |
| Study |
PRJEB32642 / GSE130212 |
| Organism |
Homo sapiens |
| Cell Type |
hESC-derived midbrain floorplate progenitors |
| Differentiation Day |
Day 25 |
| Expected Markers |
High expression of SHH, FOXA2, LMX1A; moderate OTX2, EN1 |
| Sequencing Layout |
Paired-end (R1: barcodes/UMI; R2: transcript reads) |
| Chemistry |
PIPseq T2 kit v3 chemistry |
| Cell Type | Gene Expression |
|———–|—————–|
| Floor plate progenitors |
FOXA2, FOXA1, ARX, and TFF3 |
| Dorsal forebrain progenitors |
PAX6, OTX2, EMX2 |
| Ventral tuberal hypothalamic progenitors |
NKX2-1, RAX, SIX6 |
File Setup
Download and extract single cell RNAseq data
1
2
3
4
| /work/gif3/masonbrink/USDA/05_PipseqTutorial
module load sratoolkit/3.0.0-6ikpzzj
fasterq-dump --split-files ERR14876813
|
Generate Genomic index
Option 1
Download and extract the cell ranger precomputed human reference if you have the matching version of STAR.
1
2
3
| #Ensembl GRCh38 release-95 including 10x Genomics GRCh38-2020-A prebuilt reference
wget -c https://cf.10xgenomics.com/supp/cell-exp/refdata-gex-GRCh38-2020-A.tar.gz
tar -xzvf refdata-gex-GRCh38-2020-A.tar.gz
|
Option 2
We do not have the same star version as the precomputed reference, so we are creating a STAR index from the above downloaded files “genome.fa” and “genes.gtf”.
1
2
3
| ml micromamba; micromamba activate star_env
#Generate genome index with STAR (including introns for snRNA-seq) and adjust --sjdbOverhang to (read length - 1). My reads were 151bp.
STAR --runThreadN 36 --genomeSAindexNbases 14 --runMode genomeGenerate --genomeDir STAR_index --genomeFastaFiles fasta/genome.fa --sjdbGTFfile genes/genes.gtf --sjdbOverhang 150
|
Alignment and Cell Allocation
Align reads to genome and assign reads to individual cells
Use the sample metadata to find out which read and the length of UMI and cell barcode sequences. These are typical settings with the transcript-containing paired read listed first (R2 in this case). I set ‘–soloBarcodeReadLength 0’ to avoid the automatic check of read length for R1, as my reads were 151bp for both R1 and R2.The white list is something better described in detail below.
The whitelist is the set of barcodes attributed to your cells, which can differ based on the technology you used to produce your single cell RNA-seq. With 10x kits there are a set of designated barcodes and STARsolo will automatically recogize these with ‘–soloType CB_UMI_Simple –soloCBwhitelist 10x_v3’, etc. For PiPseq, the cell barcodes are custom and thus so is the whitelist. You can align without using a whitelist ‘–soloCBwhitelist None’, but you will lose a percent of reads that have almost-perfect cell barcodes due to sequencing error. So you should always try to supply a whitelist if possible. The various barcode whitelists for 10x can be downloaded here currently https://github.com/10XGenomics/supernova/blame/master/tenkit/lib/python/tenkit/barcodes
This will assign read counts to every cell barcode present in the R1 read, as long as its second pair (transcript read) aligns to a gene in the genome. Due to sequencing error you will get many cells with very few counts as well.
1
2
3
4
5
6
7
8
9
10
11
12
| #Note that R2 is has the cell barcode + UMI (unique molecular identifier).
STAR --genomeDir STAR_index_human \
--runThreadN 36 \
--readFilesIn ERR14876813_2.fastq.gz ERR14876813_1.fastq.gz \
--soloBarcodeReadLength 0 \
--readFilesCommand zcat \
--soloType CB_UMI_Simple \
--soloCBstart 1 --soloCBlen 16 \
--soloUMIstart 17 --soloUMIlen 12 \
--soloFeatures Gene \
--soloOutFileNames ERR14876813_out/ \
--soloCBwhitelist None
|
Alignment results in Log.final.out using PiPseq settings
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| Number of input reads | 157039478
Average input read length | 151
UNIQUE READS:
Uniquely mapped reads number | 60420433
Uniquely mapped reads % | 38.47%
Average mapped length | 136.48
Number of splices: Total | 18465855
Number of splices: Annotated (sjdb) | 17744515
Number of splices: GT/AG | 17921301
Number of splices: GC/AG | 36104
Number of splices: AT/AC | 4937
Number of splices: Non-canonical | 503513
Mismatch rate per base, % | 0.96%
Deletion rate per base | 0.01%
Deletion average length | 1.45
Insertion rate per base | 0.02%
Insertion average length | 1.21
MULTI-MAPPING READS:
Number of reads mapped to multiple loci | 5419489
% of reads mapped to multiple loci | 3.45%
Number of reads mapped to too many loci | 39235
% of reads mapped to too many loci | 0.02%
UNMAPPED READS:
Number of reads unmapped: too many mismatches | 0
% of reads unmapped: too many mismatches | 0.00%
Number of reads unmapped: too short | 91110551
% of reads unmapped: too short | 58.02%
Number of reads unmapped: other | 49770
% of reads unmapped: other | 0.03%
CHIMERIC READS:
Number of chimeric reads | 0
% of chimeric reads | 0.00%
|
We a got a decent proportion of the reads to align uniquely, which will likely give us enough reads/cell to cluster. A much higher unique alignment would be ideal.
A key output to assess is the ERR14876813_out/Gene/Summary.csv
| STARsolo Metric | No Whitelist| UMI_tools Filtration | Trimmed No Whitelist | Trimmed Mapped, UMItools whitelist, Remap| Description |
|-----------------------------------------------------|-------------|----------------------|-----------------|---------------------------|-------------------------------------|
| **Number of Reads** | 157,039,478 | 116,071,096 | | | Total number of sequenced read pairs. |
| **Reads With Valid Barcodes** | 1 | 1 | | | Number of reads with valid cell barcodes. (Likely placeholder or parsing error) |
| **Sequencing Saturation** | 0.682587 | 0.30226 | | | Fraction of redundant reads; higher = more deeply sequenced. |
| **Q30 Bases in RNA read** | 0.747132 | 0.748008 | | | Fraction of RNA bases with Q ≥ 30, indicating base call accuracy. |
| **Reads Mapped to Genome: Unique+Multiple** | 0.419257 | 0.416554 | | | Fraction of reads mapped (unique + multi-mapped). |
| **Reads Mapped to Genome: Unique** | 0.384747 | 0.382292 | | | Fraction of reads that mapped uniquely to the genome. |
| **Reads Mapped to Gene: Unique+Multiple Gene** | — | - | | | Not reported (header only). |
| **Reads Mapped to Gene: Unique Gene** | 0.285561 | 0.282708 | | | Fraction of reads uniquely mapped to a gene. |
| **Estimated Number of Cells** | 2,787 | 2,148 | | | STARsolo's estimate of the number of real cells detected. |
| **Unique Reads in Cells Mapped to Gene** | 38,905,923 | 24,044,479 | | | Total gene-mapped reads from valid cells, ignoring duplicates. |
| **Fraction of Unique Reads in Cells** | 0.867576 | 0.732747 | | | Proportion of unique gene-mapped reads within valid cells. |
| **Mean Reads per Cell** | 13,959 | 11,193 | | | Average total reads per cell barcode. |
| **Median Reads per Cell** | 9,899 | 8,544 | | | Median number of reads across all valid cells. |
| **UMIs in Cells** | 10,731,984 | 16,556,235 | | | Total unique molecular identifiers (UMIs) in valid cells. |
| **Mean UMI per Cell** | 3,850 | 7,707 | | | Average number of UMIs per cell. |
| **Median UMI per Cell** | 2,856 | 6,079 | | | Median UMIs per cell. |
| **Mean Gene per Cell** | 2,215 | 1,987 | | | Average number of genes detected per cell. |
| **Median Gene per Cell** | 1,967 | 1,785 | | | Median number of genes detected per cell. |
| **Total Gene Detected** | 20,481 | 19,386 | | | Total number of genes detected across all cells. |
### Filter and fix the reads for improved alignment
When we do not have a known whitelist of cell barcodes, we have to make one ourselves. This is where it pays to know the metadata of your sample, as you need to set the expected length of the barcode pattern: C = cell barcode, N = UMI, X = ignore.
```bash
umi_tools whitelist --stdin=ERR14876813_1_extracted.fastq.gz --bc-pattern=CCCCCCCCCCCCCCCCNNNNNNNNNNNN --log2stderr > whitelist.txt
2025-07-23 16:26:29,101 INFO Top 79 cell barcodes passed the selected threshold
2025-07-23 16:26:29,101 INFO Writing out whitelist
2025-07-23 16:26:29,103 INFO Parsed 90386148 reads
2025-07-23 16:26:29,103 INFO 90386148 reads matched the barcode pattern
2025-07-23 16:26:29,103 INFO Found 74469 unique cell barcodes
2025-07-23 16:26:29,103 INFO Found 68095047 total reads matching the selected cell barcodes
2025-07-23 16:26:29,103 INFO Found 5124646 total reads which can be error corrected to the selected cell barcodes
```
## Filter out reads without a cell barcode, fix seq errors in barcodes, and add barcodes to header.
```bash
umi_tools extract --stdin=ERR14876813_1.fastq --bc-pattern=CCCCCCCCCCCCNNNNNNNN --whitelist=whitelist.txt --stdout=ERR14876813_1_extracted.fastq.gz --read2-in=ERR14876813_2.fastq --read2-out=ERR14876813_2_extracted.fastq.gz
2025-07-23 19:30:01,662 INFO Input Reads: 157039478
2025-07-23 19:30:01,662 INFO Reads output: 116071096
2025-07-23 19:30:01,662 INFO Filtered cell barcode: 40968382
```
### Align Filtered Reads
```bash
/work/gif3/masonbrink/USDA/05_PipseqTutorial
cut -f1 whitelist.txt > whitelist_clean.txt
STAR --genomeDir refdata-gex-GRCh38-2020-A/STAR_index \
--runThreadN 36 \
--readFilesIn ERR14876813_2_extracted.fastq.gz ERR14876813_1_extracted.fastq.gz \
--readFilesCommand zcat \
--soloType CB_UMI_Simple \
--soloFeatures Gene \
--soloOutFileNames ERR14876813_extracted_out/ \
--soloCBwhitelist whitelist_clean.txt \
--soloBarcodeReadLength 0 \
--soloCBstart 1 --soloCBlen 12 \
--soloUMIstart 13 --soloUMIlen 8
```
### Alignment rates
You see that my number of uniquely aligned reads has decreased, which gives a false impression of what umi_tools has done. We know that umi_tools has removed all R1 reads and their mates (R2) that do not have any similarity to a cell barcode, thereby removing all ambient RNA not assigned to a cell.
# Here there appears to be an issue with assignment that was not present above.
```
Started job on | Aug 21 11:29:14
Started mapping on | Aug 21 11:36:40
Finished on | Aug 21 11:50:12
Mapping speed, Million of reads per hour | 514.60
Number of input reads | 116071096
Average input read length | 151
UNIQUE READS:
Uniquely mapped reads number | 44372994
Uniquely mapped reads % | 38.23%
Average mapped length | 136.45
Number of splices: Total | 13522778
Number of splices: Annotated (sjdb) | 12992675
Number of splices: GT/AG | 13122165
Number of splices: GC/AG | 26428
Number of splices: AT/AC | 3562
Number of splices: Non-canonical | 370623
Mismatch rate per base, % | 0.96%
Deletion rate per base | 0.01%
Deletion average length | 1.44
Insertion rate per base | 0.02%
Insertion average length | 1.21
MULTI-MAPPING READS:
Number of reads mapped to multiple loci | 3976850
% of reads mapped to multiple loci | 3.43%
Number of reads mapped to too many loci | 28755
% of reads mapped to too many loci | 0.02%
UNMAPPED READS:
Number of reads unmapped: too many mismatches | 0
% of reads unmapped: too many mismatches | 0.00%
Number of reads unmapped: too short | 67661868
% of reads unmapped: too short | 58.29%
Number of reads unmapped: other | 30629
% of reads unmapped: other | 0.03%
CHIMERIC READS:
Number of chimeric reads | 0
% of chimeric reads | 0.00%
```
### Quality check -- Is it that our R2 reads contain a large proportion of polyA or PolyT in the reads?
**polyA in R1 as control**
```
total=$(zcat ERR14876813_1_extracted.fastq.gz | awk 'NR%4==2' | wc -l)
poly_any=$(zcat ERR14876813_1_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'A{20,}' | wc -l)
poly_trail=$(zcat ERR14876813_1_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'A{20,}$' | wc -l)
awk -v t=$total -v a=$poly_any -v b=$poly_trail 'BEGIN{if(t==0){print "no reads"; exit} printf "any A>=20: %d/%d (%.2f%%)\n", a, t, a/t*100; printf "trailing A>=20: %d/%d (%.2f%%)\n", b, t, b/t*100; }'
any A>=20: 189717/116071096 (0.16%)
trailing A>=20: 20820/116071096 (0.02%)
```
**polyT in R1 as control**
```
poly_any=$(zcat ERR14876813_1_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'T{20,}' | wc -l)
poly_trail=$(zcat ERR14876813_1_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'T{20,}$' | wc -l)
awk -v t=$total -v a=$poly_any -v b=$poly_trail 'BEGIN{if(t==0){print "no reads"; exit} printf "any T>=20: %d/%d (%.2f%%)\n", a, t, a/t*100; printf "trailing T>=20: %d/%d (%.2f%%)\n", b, t, b/t*100; }'
any T>=20: 104280453/116071096 (89.84%)
trailing T>=20: 2260708/116071096 (1.95%)
```
**polyA in R2**
```
poly_any=$(zcat ERR14876813_2_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'A{20,}' | wc -l)
poly_trail=$(zcat ERR14876813_2_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'A{20,}$' | wc -l)
awk -v t=$total -v a=$poly_any -v b=$poly_trail 'BEGIN{if(t==0){print "no reads"; exit} printf "any A>=20: %d/%d (%.2f%%)\n", a, t, a/t*100; printf "trailing A>=20: %d/%d (%.2f%%)\n", b, t, b/t*100; }'
any A>=20: 74618826/116071096 (64.29%)
trailing A>=20: 7990572/116071096 (6.88%)
```
**polyT in R2**
```
poly_any=$(zcat ERR14876813_2_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'T{20,}' | wc -l)
poly_trail=$(zcat ERR14876813_2_extracted.fastq.gz | awk 'NR%4==2' | grep -i -E 'T{20,}$' | wc -l)
awk -v t=$total -v a=$poly_any -v b=$poly_trail 'BEGIN{if(t==0){print "no reads"; exit} printf "any T>=20: %d/%d (%.2f%%)\n", a, t, a/t*100; printf "trailing T>=20: %d/%d (%.2f%%)\n", b, t, b/t*100; }'
any T>=20: 146476/116071096 (0.13%)
trailing T>=20: 1376/116071096 (0.00%)
```
We have lots of PolyA sequences in our R2 (cDNA) read, the amount of polyT in R1 is negligable as we are only concerned with the cell barcode and UMI. It is possible that this extra sequence at the end of R1 is CDNA transcript, something to be investigated if mapping rates are low.
### Trim the R2 reads to obtain better mapping.
```bash
ml py-cutadapt;cutadapt -j 36 -A file:adapterSequences.fa -A A{15} -m 25 -o TrimERR14876813_1.fq.gz -p TrimERR14876813_2.fq.gz ERR14876813_1.fastq ERR14876813_2.fastq --pair-filter=any > cutadapt_report.txt
vi adapterSequences.fa
>Illumina universal adapter
AGATCGGAAGAGCACACGTCTGAACTCCAGTCAC
>Template switch oligo TSO ISPCR motif short
AAGCAGTGGT
>Template switch oligo TSO ISPCR motif long
AAGCAGTGGTATCAACGCAGAGTAC
```
**Results Summary**
```
=== Summary ===
Total read pairs processed: 157,039,478
Read 2 with adapter: 129,257,289 (82.3%)
== Read fate breakdown ==
Pairs that were too short: 31,759,468 (20.2%)
Pairs written (passing filters): 125,280,010 (79.8%)
Total basepairs processed: 47,425,922,356 bp
Read 1: 23,712,961,178 bp
Read 2: 23,712,961,178 bp
Total written (filtered): 31,485,806,925 bp (66.4%)
Read 1: 18,917,281,510 bp
Read 2: 12,568,525,415 bp
```
##### Remap these trimmed reads
Theoretically these reads should more accurately map to the reference genome, giving a better representation of cell expression.
```bash
STAR --genomeDir refdata-gex-GRCh38-2020-A/STAR_index \
--runThreadN 36 \
--readFilesIn TrimERR14876813_2.fq.gz TrimERR14876813_1.fq.gz \
--soloType CB_UMI_Simple \
--soloFeatures Gene \
--soloOutFileNames ERR14876813_Trim_out/ \
--soloBarcodeReadLength 0 \
--soloCBstart 1 --soloCBlen 16 \
--soloUMIstart 17 --soloUMIlen 12 \
--readFilesCommand zcat \
--soloCBwhitelist None
```
**Results of Trimmed Read Alignment**
```
Started job on | Aug 27 13:47:42
Started mapping on | Aug 27 13:51:59
Finished on | Aug 27 14:00:34
Mapping speed, Million of reads per hour | 875.74
Number of input reads | 125280010
Average input read length | 100
UNIQUE READS:
Uniquely mapped reads number | 98746317
Uniquely mapped reads % | 78.82%
Average mapped length | 102.55
Number of splices: Total | 22621733
Number of splices: Annotated (sjdb) | 22283410
Number of splices: GT/AG | 22427419
Number of splices: GC/AG | 38377
Number of splices: AT/AC | 4574
Number of splices: Non-canonical | 151363
Mismatch rate per base, % | 0.23%
Deletion rate per base | 0.01%
Deletion average length | 1.32
Insertion rate per base | 0.02%
Insertion average length | 1.18
MULTI-MAPPING READS:
Number of reads mapped to multiple loci | 20154650
% of reads mapped to multiple loci | 16.09%
Number of reads mapped to too many loci | 448146
% of reads mapped to too many loci | 0.36%
UNMAPPED READS:
Number of reads unmapped: too many mismatches | 0
% of reads unmapped: too many mismatches | 0.00%
Number of reads unmapped: too short | 5840301
% of reads unmapped: too short | 4.66%
Number of reads unmapped: other | 90596
% of reads unmapped: other | 0.07%
CHIMERIC READS:
Number of chimeric reads | 0
% of chimeric reads | 0.00%
```
| STARsolo Metric | No Whitelist| UMI_tools Filtration | Trimmed No Whitelist | Trimmed Mapped, UMItools whitelist, Remap| Description |
|-----------------------------------------------------|-------------|----------------------|----------------------|------------------------------------------|-------------------------------------|
| **Number of Reads** | 157,039,478 | 116,071,096 | 125,280,010 | | Total number of sequenced read pairs. |
| **Sequencing Saturation** | 0.682587 | 0.30226 | 0.778451 | | Fraction of redundant reads; higher = more deeply sequenced. |
| **Q30 Bases in RNA read** | 0.747132 | 0.748008 | 0.938203 | | Fraction of RNA bases with Q ≥ 30, indicating base call accuracy. |
| **Reads Mapped to Genome: Unique+Multiple** | 0.419257 | 0.416554 | 0.949082 | | Fraction of reads mapped (unique + multi-mapped). |
| **Reads Mapped to Genome: Unique** | 0.384747 | 0.382292 | 0.788205 | | Fraction of reads that mapped uniquely to the genome. |
| **Reads Mapped to Gene: Unique Gene** | 0.285561 | 0.282708 | 0.841158 | | Fraction of reads uniquely mapped to a gene. |
| **Estimated Number of Cells** | 2,787 | 2,148 | 2,874 | | STARsolo's estimate of the number of real cells detected. |
| **Unique Reads in Cells Mapped to Gene** | 38,905,923 | 24,044,479 | 92,397,559 | | Total gene-mapped reads from valid cells, ignoring duplicates. |
| **Fraction of Unique Reads in Cells** | 0.867576 | 0.732747 | 0.876801 | | Proportion of unique gene-mapped reads within valid cells. |
| **Mean Reads per Cell** | 13,959 | 11,193 | 32,149 | | Average total reads per cell barcode. |
| **Median Reads per Cell** | 9,899 | 8,544 | 22,761 | | Median number of reads across all valid cells. |
| **UMIs in Cells** | 10,731,984 | 16,556,235 | 17,026,462 | | Total unique molecular identifiers (UMIs) in valid cells. |
| **Mean UMI per Cell** | 3,850 | 7,707 | 5,924 | | Average number of UMIs per cell. |
| **Median UMI per Cell** | 2,856 | 6,079 | 4,374 | | Median UMIs per cell. |
| **Mean Gene per Cell** | 2,215 | 1,987 | 3,032 | | Average number of genes detected per cell. |
| **Median Gene per Cell** | 1,967 | 1,785 | 2,748 | | Median number of genes detected per cell. |
| **Total Gene Detected** | 20,481 | 19,386 | 22,882 | | Total number of genes detected across all cells. |
These stats are improving from trimming and it seems apparent that Umitools may be pulling out ambient RNA junk and calling them cells.
### Create a whitelist from mapped reads
```
Extract all reads that mapped without using a whitelist
samtools view -F 4 Aligned.out.sam | awk '{print $1}' | sort -u > mapped_readnames.txt
seqtk subseq TrimERR14876813_1.fq.gz mapped_readnames.txt > TrimERR14876813_mapped_R1.fastq &
seqtk subseq TrimERR14876813_2.fq.gz mapped_readnames.txt > TrimERR14876813_mapped_R2.fastq &
umi_tools whitelist --stdin TrimERR14876813_mapped_R1.fastq --bc-pattern=CCCCCCCCCCCCCCCCNNNNNNNNNNNN >TrimAlignedExtractedwhitelist.tx
#Top 1340 cell barcodes passed the selected threshold
## 2025-08-27 15:30:40,695 INFO 100000001 reads matched the barcode pattern
## 2025-08-27 15:30:40,695 INFO Found 419287 unique cell barcodes
## 2025-08-27 15:30:40,695 INFO Found 67343963 total reads matching the selected cell barcodes
## 2025-08-27 15:30:40,696 INFO Found 8703676 total reads which can be error corrected to the selected cell barcodes
#format the white list to just be a list of barcodes
cut -f 1 TrimAlignedExtractedwhitelist.txt|awk 'substr($1,1,1)!="#"' >clean_whitelist.txt
```
### Realign all trimmed reads with whitelist above
```
STAR --genomeDir refdata-gex-GRCh38-2020-A/STAR_index \
--runThreadN 36 \
--readFilesIn TrimERR14876813_2.fq.gz TrimERR14876813_1.fq.gz \
--soloType CB_UMI_Simple \
--soloFeatures Gene \
--soloOutFileNames ERR14876813_Trim_out/ \
--soloBarcodeReadLength 0 \
--soloCBstart 1 --soloCBlen 16 \
--soloUMIstart 17 --soloUMIlen 12 \
--readFilesCommand zcat \
--soloCBwhitelist clean_whitelist.txt
```
**Results**
```
Started job on | Aug 27 16:37:46
Started mapping on | Aug 27 16:38:53
Finished on | Aug 27 16:46:42
Mapping speed, Million of reads per hour | 961.64
Number of input reads | 125280010
Average input read length | 100
UNIQUE READS:
Uniquely mapped reads number | 98746317
Uniquely mapped reads % | 78.82%
Average mapped length | 102.55
Number of splices: Total | 22621733
Number of splices: Annotated (sjdb) | 22283410
Number of splices: GT/AG | 22427419
Number of splices: GC/AG | 38377
Number of splices: AT/AC | 4574
Number of splices: Non-canonical | 151363
Mismatch rate per base, % | 0.23%
Deletion rate per base | 0.01%
Deletion average length | 1.32
Insertion rate per base | 0.02%
Insertion average length | 1.18
MULTI-MAPPING READS:
Number of reads mapped to multiple loci | 20154650
% of reads mapped to multiple loci | 16.09%
Number of reads mapped to too many loci | 448146
% of reads mapped to too many loci | 0.36%
UNMAPPED READS:
Number of reads unmapped: too many mismatches | 0
% of reads unmapped: too many mismatches | 0.00%
Number of reads unmapped: too short | 5840301
% of reads unmapped: too short | 4.66%
Number of reads unmapped: other | 90596
% of reads unmapped: other | 0.07%
CHIMERIC READS:
Number of chimeric reads | 0
% of chimeric reads | 0.00%
```
| STARsolo Metric | No Whitelist| UMI_tools Filtration | Trimmed No Whitelist | Trimmed Mapped, UMItools whitelist, Remap| Description |
|-----------------------------------------------------|-------------|----------------------|----------------------|------------------------------------------|-------------------------------------|
| **Number of Reads** | 157,039,478 | 116,071,096 | 125,280,010 | 125,280,010 | Total number of sequenced read pairs. |
| **Sequencing Saturation** | 0.682587 | 0.30226 | 0.778451 | 0.825583 | Fraction of redundant reads; higher = more deeply sequenced. |
| **Q30 Bases in RNA read** | 0.747132 | 0.748008 | 0.938203 | 0.938203 | Fraction of RNA bases with Q ≥ 30, indicating base call accuracy. |
| **Reads Mapped to Genome: Unique+Multiple** | 0.419257 | 0.416554 | 0.949082 | 0.949082 | Fraction of reads mapped (unique + multi-mapped). |
| **Reads Mapped to Genome: Unique** | 0.384747 | 0.382292 | 0.788205 | 0.788205 | Fraction of reads that mapped uniquely to the genome. |
| **Reads Mapped to Gene: Unique Gene** | 0.285561 | 0.282708 | 0.841158 | 0.642806 | Fraction of reads uniquely mapped to a gene. |
| **Estimated Number of Cells** | 2,787 | 2,148 | 2,874 | 1,340 | STARsolo's estimate of the number of real cells detected. |
| **Unique Reads in Cells Mapped to Gene** | 38,905,923 | 24,044,479 | 92,397,559 | 80,530,725 | Total gene-mapped reads from valid cells, ignoring duplicates. |
| **Fraction of Unique Reads in Cells** | 0.867576 | 0.732747 | 0.876801 | 1 | Proportion of unique gene-mapped reads within valid cells. |
| **Mean Reads per Cell** | 13,959 | 11,193 | 32,149 | 60,097 | Average total reads per cell barcode. |
| **Median Reads per Cell** | 9,899 | 8,544 | 22,761 | 50,789 | Median number of reads across all valid cells. |
| **UMIs in Cells** | 10,731,984 | 16,556,235 | 17,026,462 | 14,045,959 | Total unique molecular identifiers (UMIs) in valid cells. |
| **Mean UMI per Cell** | 3,850 | 7,707 | 5,924 | 10,482 | Average number of UMIs per cell. |
| **Median UMI per Cell** | 2,856 | 6,079 | 4,374 | 9,460 | Median UMIs per cell. |
| **Mean Gene per Cell** | 2,215 | 1,987 | 3,032 | 4,472 | Average number of genes detected per cell. |
| **Median Gene per Cell** | 1,967 | 1,785 | 2,748 | 4,319 | Median number of genes detected per cell. |
| **Total Gene Detected** | 20,481 | 19,386 | 22,882 | 22,546 | Total number of genes detected across all cells. |
### Seurat Clustering and assessement of Hedgehog associated genes
```bash
ml seurat/develop20210621
run_seurat_env
```
```R
# Load libraries
library(Seurat)
library(Matrix)
library(dplyr)
library(ggplot2)
library(patchwork)
# Set data directory (change if needed)
data_dir <- "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/"
# Load 10x Genomics matrix
counts <- Read10X(data.dir = data_dir)
if (is.list(counts)) counts <- counts[[1]]
# Create Seurat object
seurat_obj <- CreateSeuratObject(counts = counts, project = "hesc_SHH")
# Basic QC (optional but recommended)
seurat_obj[["percent.mt"]] <- PercentageFeatureSet(seurat_obj, pattern = "^MT-")
VlnPlot(seurat_obj, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"))
# Standard preprocessing
seurat_obj <- NormalizeData(seurat_obj)
seurat_obj <- FindVariableFeatures(seurat_obj)
seurat_obj <- ScaleData(seurat_obj)
seurat_obj <- RunPCA(seurat_obj, npcs = 30)
ElbowPlot(seurat_obj) # Optional: to determine optimal dims
# Dimensional reduction and clustering
seurat_obj <- RunUMAP(seurat_obj, dims = 1:20)
seurat_obj <- FindNeighbors(seurat_obj, dims = 1:20)
seurat_obj <- FindClusters(seurat_obj, resolution = 0.5)
# Optional: Hedgehog-specific analysis
# If you have a list of hedgehog signaling genes (e.g., SHH, GLI1, PTCH1)
hedgehog_genes <- c("FOXA2", "FOXA1", "ARX", "TFF3", "PAX6", "OTX2", "EMX2", "NKX2-1", "RAX", "SIX6")
seurat_obj <- AddModuleScore(seurat_obj, features = list(hedgehog_genes), name = "HedgehogScore")
# Plot clusters and expression of hedgehog genes
p1 <- DimPlot(seurat_obj, label = TRUE) + ggtitle("UMAP: Clusters")
p2 <- FeaturePlot(seurat_obj, features = "HedgehogScore1") + ggtitle("Hedgehog Pathway Score")
# Display side-by-side
print(p1 + p2)
# Save plots to file
png("UMAP_Clusters.png", width = 800, height = 600)
print(p1)
dev.off()
png("UMAP_HedgehogScore.png", width = 800, height = 600)
print(p2)
dev.off()
saveRDS(seurat_obj, "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/03_Clustered.rds")
```
**Filtered read alignment with trimming, umi_tools, and genome mapping**
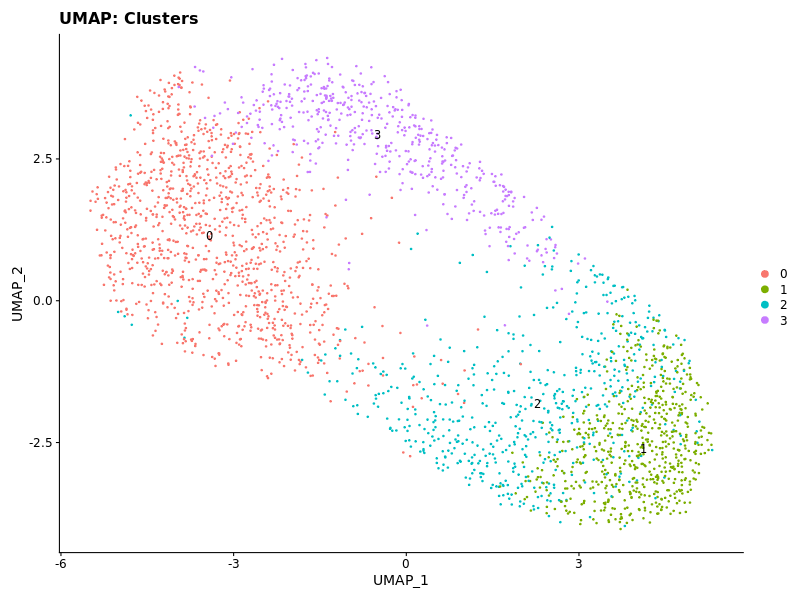
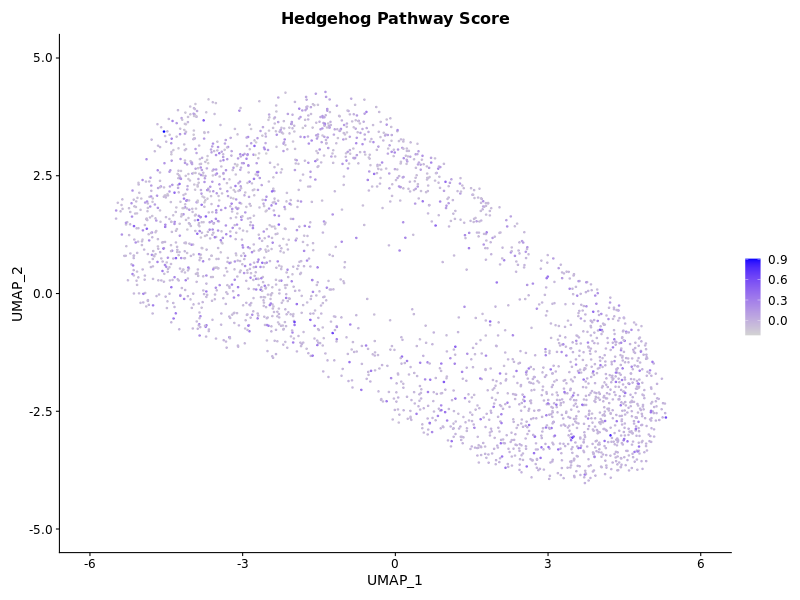
The clusters were not highly distinct in the first attempt, so increased resolution to reflect what was done in their publication.
Find better marker genes
* Floor plate module based on FOXA2, FOXA1, ARX, and TFF3 -- cells with a score greater than 0.25 were considered floor plate cells
* dorsal forebrain progenitors on PAX6, OTX2, EMX2
* ventral tuberal hypothalamic prgenitors on NKX2-1, RAX, SIX6
### Create a dotplot of pub-suggested marker genes
```R
library(Seurat)
library(ggplot2)
library(patchwork)
set.seed(123)
# Load new Seurat object
seu <- readRDS(file = "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/03_Clustered.rds")
# Check clusters
cat("Cluster sizes:\n")
print(table(seu$seurat_clusters))
# Remove trailing "-1" from gene names if present
cleaner <- function(x) sub("-1$", "", x)
counts <- GetAssayData(seu, assay = "RNA", layer = "counts")
data <- GetAssayData(seu, assay = "RNA", layer = "data")
rownames(counts) <- cleaner(rownames(counts))
rownames(data) <- cleaner(rownames(data))
# Make cleaned assay
assay_clean <- CreateAssayObject(counts = counts)
assay_clean <- SetAssayData(assay_clean, layer = "data", new.data = data)
seu[["RNA_clean"]] <- assay_clean
DefaultAssay(seu) <- "RNA_clean"
# Marker genes
markers <- c("FOXA2", "FOXA1", "ARX", "TFF3", "PAX6", "OTX2", "EMX2", "NKX2", "RAX", "SIX6")
# Match against dataset
seu_genes <- rownames(GetAssayData(seu, assay = "RNA_clean"))
matched <- intersect(markers, seu_genes)
missing <- setdiff(markers, seu_genes)
cat("✅ Found marker genes:\n")
print(matched)
cat("❌ Missing marker genes:\n")
print(missing)
p1 <- DotPlot(seu, features = matched) + ggtitle("Marker Expression by Cluster") & RotatedAxis()
# DotPlot
png("Marker_Expression_by_Cluster.png", width = 800, height = 600)
print(p1)
dev.off()
# Save updated object
saveRDS(seu, "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/03_Clustered_cleaned.rds")
```
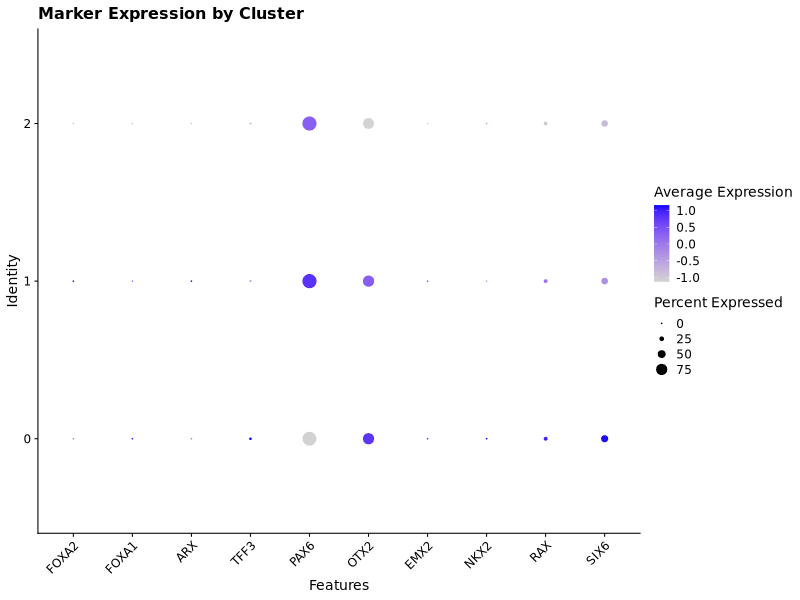
These markers were not distinct among the different clusters, so we needed to make a different approach to identify the different types of cells in the different clusters.
### Identify top 30 genes differentially expressed among the clusters
```R
library(Seurat)
library(dplyr)
set.seed(123)
# Load data
seu <- readRDS(file ="/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/03_Clustered.rds")
table(seu$seurat_clusters)
## continuing with res 1
# Find markers
de_genes <- FindAllMarkers(seu,
min.pct = 0.25,
logfc.threshold = 0.25)
sig_markers <- de_genes %>%
filter(p_val_adj < 0.05) %>%
arrange(desc(avg_log2FC))
unique_genes <- unique(sig_markers$gene)
length(unique_genes)
# Get top markers per cluster based on avg_log2FC
top_markers_per_cluster <- sig_markers %>%
filter(avg_log2FC > 0) %>%
group_by(cluster) %>%
slice_max(order_by = avg_log2FC, n = 30) %>%
ungroup()
# build the gene × cluster count matrix
mat <- table(sig_markers$gene, sig_markers$cluster)
df_wide <- as.data.frame.matrix(mat)
head(df_wide)
## Save files
write.csv(sig_markers, "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/Significant_markers.csv", row.names = FALSE)
write.csv(df_wide, "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/Marker_presence_matrix.csv", row.names = TRUE)
write.csv(top_markers_per_cluster, "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/Top30_markers_per_cluster.csv", row.names = FALSE)
```
These were informative, though there were only ~5 genes for cluster 3 and 12 for cluster 2. Going to rerun the framework with these top 30 genes.
|Adjusted P value|Cluster | Gene |
|----------------|--------|------|
| 8.57608955772113e-17 | 0 | FUNDC1 |
| 3.9005065420351e-17 | 0 | FAM71D |
| 6.93791486146789e-17 | 0 | PMPCA |
| 8.18478413137096e-19 | 0 | DCAF7 |
| 4.26263193913731e-16 | 0 | SKP2 |
| 1.05083504411023e-19 | 0 | SFT2D1 |
| 8.02207384641925e-18 | 0 | GPR19 |
| 6.88098317829902e-22 | 0 | RPL26L1 |
| 2.54509437268097e-16 | 0 | ADK |
| 3.26949281361046e-22 | 0 | GANAB |
|1.97144178975535e-200 | 1 | RPL35A |
|4.46639715924085e-205 | 1 | RPS17 |
|2.58131811268766e-203 | 1 | RPS4X |
|4.60614229184367e-198 | 1 | RPL31 |
|4.96350956258184e-196 | 1 | RPS18 |
|2.02820222796243e-198 | 1 | RPS6 |
|1.25012770813508e-198 | 1 | RPL41 |
|4.31012976148348e-202 | 1 | RPS14 |
|1.31393523012029e-182 | 1 | RPL23 |
|5.68364220904455e-188 | 1 | RPL8 |
|4.59597239276741e-06 | 2 | DCAF7 |
|2.7547688511436e-07 | 2 | FAM104B |
|5.76505764746112e-07 | 2 | WDYHV1 |
|1.12550825024702e-08 | 2 | DUSP6 |
|2.39645541234559e-09 | 2 | SPC24 |
|1.05382469300279e-06 | 2 | YEATS4 |
|1.92923018698408e-07 | 2 | MYH9 |
|1.71575660154685e-10 | 2 | LMNB1 |
|9.49329175273712e-09 | 2 | WBP11 |
|1.56061397079898e-09 | 2 | CDCA8 |
|1.2943813041741e-09 | 2 | CPSF3 |
|2.10333896368509e-08 | 2 | COMMD1 |
|2.78368486676784e-19 | 3 | NCL |
|8.41139937914575e-30 | 3 | MALAT1 |
|2.46050422193597e-16 | 3 | ANP32E |
|1.8645555634698e-07 | 3 | TAF15 |
|3.93674111668568e-30 | 3 | SMC1A |
# Rerun the above framework with these top 30 genes in use.
```bash
ml seurat/develop20210621
run_seurat_env
```
### Create a dotplot of gene expression across clusters
```R
library(Seurat)
library(ggplot2)
library(patchwork)
set.seed(123)
# Load new Seurat object
seu <- readRDS(file = "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/03_Clustered_cleaned.rds")
# Check clusters
cat("Cluster sizes:\n")
print(table(seu$seurat_clusters))
# Remove trailing "-1" from gene names if present
cleaner <- function(x) sub("-1$", "", x)
counts <- GetAssayData(seu, assay = "RNA", layer = "counts")
data <- GetAssayData(seu, assay = "RNA", layer = "data")
rownames(counts) <- cleaner(rownames(counts))
rownames(data) <- cleaner(rownames(data))
# Make cleaned assay
assay_clean <- CreateAssayObject(counts = counts)
assay_clean <- SetAssayData(assay_clean, layer = "data", new.data = data)
seu[["RNA_clean"]] <- assay_clean
DefaultAssay(seu) <- "RNA_clean"
# Marker genes
markers <- c(
'HMGB2','NACA','RPL11','RPS17','RPS20','RPS23','ALPL','ANP32A','ANP32E','APLP2','ASF1B','ATF2','CCNA2','CDC25C','CDC7','CDCA3','CDCA5','CENPU'
)
# Match against dataset
seu_genes <- rownames(GetAssayData(seu, assay = "RNA_clean"))
matched <- intersect(markers, seu_genes)
missing <- setdiff(markers, seu_genes)
cat("✅ Found marker genes:\n")
print(matched)
cat("❌ Missing marker genes:\n")
print(missing)
# DotPlot
DotPlot(seu, features = matched) +
ggtitle("Marker Expression by Cluster") & RotatedAxis()
```
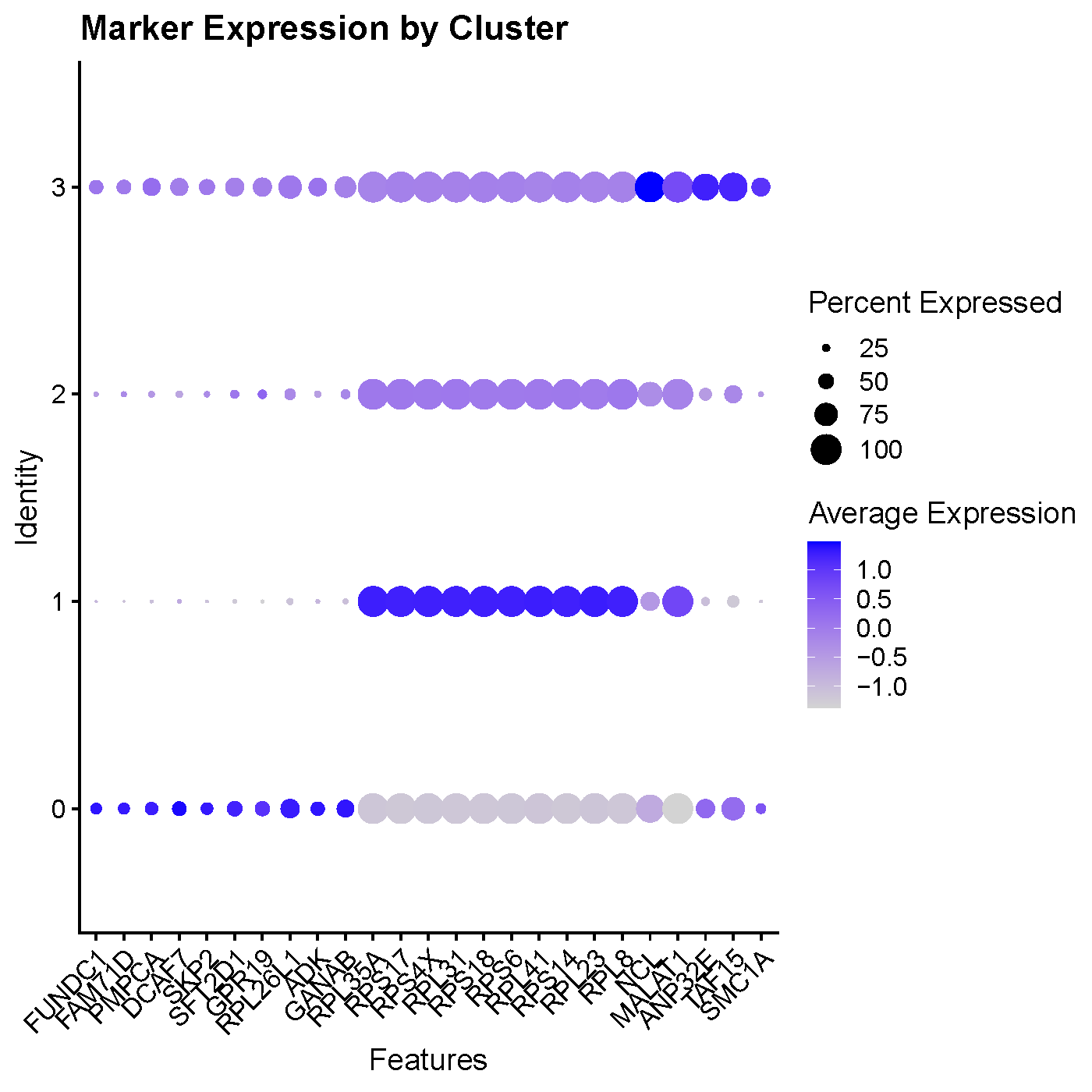
### Display Expression of Cluster 0
```R
# Load libraries
library(Seurat)
library(Matrix)
library(dplyr)
library(ggplot2)
library(patchwork)
# Set data directory (change if needed)
data_dir <- "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/"
# Load 10x Genomics matrix
counts <- Read10X(data.dir = data_dir)
if (is.list(counts)) counts <- counts[[1]]
# Create Seurat object
seurat_obj <- CreateSeuratObject(counts = counts, project = "hesc_SHH")
# Basic QC (optional but recommended)
#seurat_obj[["percent.mt"]] <- PercentageFeatureSet(seurat_obj, pattern = "^MT-")
#VlnPlot(seurat_obj, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"))
# Standard preprocessing
seurat_obj <- NormalizeData(seurat_obj)
seurat_obj <- FindVariableFeatures(seurat_obj)
seurat_obj <- ScaleData(seurat_obj)
seurat_obj <- RunPCA(seurat_obj, npcs = 30)
#ElbowPlot(seurat_obj) # Optional: to determine optimal dims
# Dimensional reduction and clustering
seurat_obj <- RunUMAP(seurat_obj, dims = 1:20)
seurat_obj <- FindNeighbors(seurat_obj, dims = 1:20)
seurat_obj <- FindClusters(seurat_obj, resolution = 0.5)
# Optional: Hedgehog-specific analysis
# If you have a list of hedgehog signaling genes (e.g., SHH, GLI1, PTCH1)
cluster0_genes <- c('FUNDC1', 'FAM71D', 'PMPCA', 'DCAF7', 'SKP2', 'SFT2D1', 'GPR19', 'RPL26L1', 'ADK', 'GANAB', 'PSMC6', 'AK6', 'CSE1L', 'KTN1', 'PTTG1IP', 'PIGT', 'FH', 'AAGAB', 'EXOSC1', 'CHCHD3', 'NARS', 'DENR', 'TAF6', 'GET1', 'PYCR1', 'CHCHD6', 'TMEM128', 'CLK3', 'DDX41', 'UBAC2')
seurat_obj <- AddModuleScore(seurat_obj, features = list(cluster0_genes), name = "Cluster0Score")
# Plot clusters and expression of hedgehog genes
p1 <- DimPlot(seurat_obj, label = TRUE) + ggtitle("UMAP: Clusters")
p2 <- FeaturePlot(seurat_obj, features = "Cluster0Score1") + ggtitle("Cluster_0 Top 30 DEG")
# side-by-side
png("Combine_Cluster0_Expression_Scores.png", width = 800, height = 600)
print(p1 + p2)
dev.off()
```
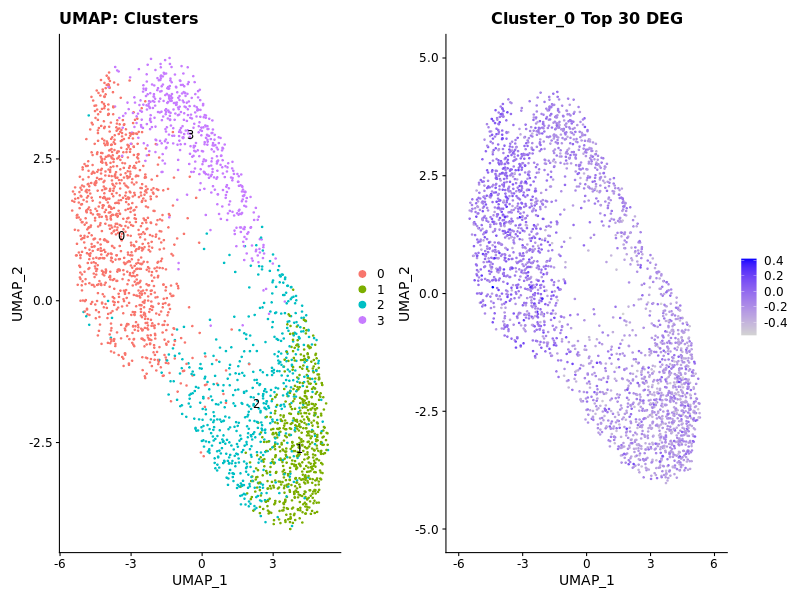
### Display Expression of Cluster 1
```R
# Load libraries
library(Seurat)
library(Matrix)
library(dplyr)
library(ggplot2)
library(patchwork)
# Set data directory (change if needed)
data_dir <- "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/"
# Load 10x Genomics matrix
counts <- Read10X(data.dir = data_dir)
if (is.list(counts)) counts <- counts[[1]]
# Create Seurat object
seurat_obj <- CreateSeuratObject(counts = counts, project = "hesc_SHH")
# Basic QC (optional but recommended)
#eurat_obj[["percent.mt"]] <- PercentageFeatureSet(seurat_obj, pattern = "^MT-")
#VlnPlot(seurat_obj, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"))
# Standard preprocessing
seurat_obj <- NormalizeData(seurat_obj)
seurat_obj <- FindVariableFeatures(seurat_obj)
seurat_obj <- ScaleData(seurat_obj)
seurat_obj <- RunPCA(seurat_obj, npcs = 30)
#ElbowPlot(seurat_obj) # Optional: to determine optimal dims
# Dimensional reduction and clustering
seurat_obj <- RunUMAP(seurat_obj, dims = 1:20)
seurat_obj <- FindNeighbors(seurat_obj, dims = 1:20)
seurat_obj <- FindClusters(seurat_obj, resolution = 0.5)
# Optional: Hedgehog-specific analysis
# If you have a list of hedgehog signaling genes (e.g., SHH, GLI1, PTCH1)
cluster1_genes <- c('RPL35A', 'RPS17', 'RPS4X', 'RPL31', 'RPS18', 'RPS6', 'RPL41', 'RPS14', 'RPL23', 'RPL8', 'RPLP0', 'RPL13', 'RPL11', 'RPS3', 'RPL18', 'RPS19', 'RPL35', 'RPL34', 'RPL37A', 'RPS16', 'RPS21', 'RPLP1', 'RPS29', 'RPL36', 'FTH1', 'RPL17', 'RPS8', 'RPS27', 'RPL32', 'DLK1')
seurat_obj <- AddModuleScore(seurat_obj, features = list(cluster1_genes), name = "Cluster1Score")
# Plot clusters and expression of hedgehog genes
p1 <- DimPlot(seurat_obj, label = TRUE) + ggtitle("UMAP: Clusters")
p2 <- FeaturePlot(seurat_obj, features = "Cluster1Score1") + ggtitle("Cluster_1 Top 30 DEG")
# side-by-side
png("Combine_Cluster1_Expression_Scores.png", width = 800, height = 600)
print(p1 + p2)
dev.off()
```
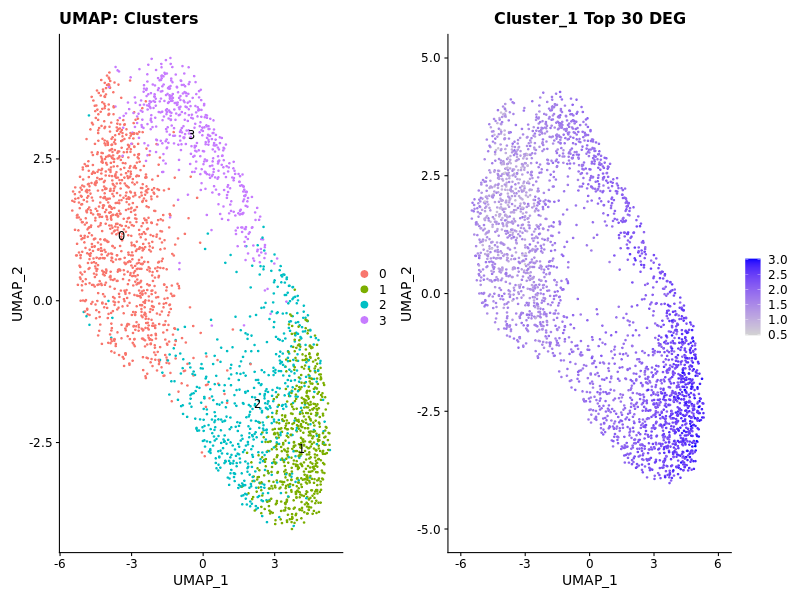
### Display Expression of Cluster 3
```R
# Load libraries
library(Seurat)
library(Matrix)
library(dplyr)
library(ggplot2)
library(patchwork)
# Set data directory (change if needed)
data_dir <- "/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/"
# Load 10x Genomics matrix
counts <- Read10X(data.dir = data_dir)
if (is.list(counts)) counts <- counts[[1]]
# Create Seurat object
seurat_obj <- CreateSeuratObject(counts = counts, project = "hesc_SHH")
# Basic QC (optional but recommended)
#eurat_obj[["percent.mt"]] <- PercentageFeatureSet(seurat_obj, pattern = "^MT-")
#VlnPlot(seurat_obj, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"))
# Standard preprocessing
seurat_obj <- NormalizeData(seurat_obj)
seurat_obj <- FindVariableFeatures(seurat_obj)
seurat_obj <- ScaleData(seurat_obj)
seurat_obj <- RunPCA(seurat_obj, npcs = 30)
#ElbowPlot(seurat_obj) # Optional: to determine optimal dims
# Dimensional reduction and clustering
seurat_obj <- RunUMAP(seurat_obj, dims = 1:20)
seurat_obj <- FindNeighbors(seurat_obj, dims = 1:20)
seurat_obj <- FindClusters(seurat_obj, resolution = 0.5)
# Optional: Hedgehog-specific analysis
# If you have a list of hedgehog signaling genes (e.g., SHH, GLI1, PTCH1)
cluster3_genes <- c('NCL', 'MALAT1', 'ANP32E', 'TAF15', 'SMC1A')
seurat_obj <- AddModuleScore(seurat_obj, features = list(cluster3_genes), name = "Cluster3Score")
# Plot clusters and expression of hedgehog genes
p1 <- DimPlot(seurat_obj, label = TRUE) + ggtitle("UMAP: Clusters")
p2 <- FeaturePlot(seurat_obj, features = "Cluster3Score1") + ggtitle("Cluster_3 Top 5 DEG")
# side-by-side
png("Combine_Cluster3_Expression_Scores.png", width = 800, height = 600)
print(p1 + p2)
dev.off()
```
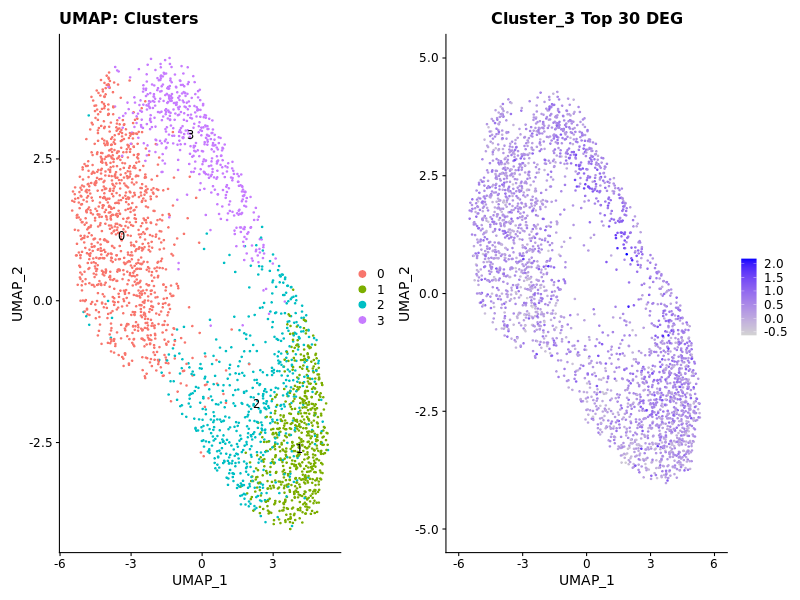
### Using the wrong reference for your existing human single cell dataset can be catastrophic!
```
https://www.ebi.ac.uk/biostudies/arrayexpress/studies/E-MTAB-3929
I used ebi's arrayExpress to find a counts matrix for "Single-cell RNA-seq reveal lineage formation and X-chromosome dosage compensation in human preimplantation embryos".
```
### Apply reference labels to my dataset
```R
library(Seurat)
library(dplyr)
ref_counts <- read.delim("counts.txt", row.names = 1, check.names = FALSE)
ref_seurat <- CreateSeuratObject(counts = ref_counts, project = "GSE76381")
metadata <- read.delim("E-MTAB-3929.sdrf.txt", check.names = FALSE)
metadata <- metadata %>%
select(`Source Name`, `Characteristics[inferred lineage]`) %>%
rename(cell_id = `Source Name`, cell_type = `Characteristics[inferred lineage]`) %>%
filter(cell_id %in% colnames(ref_seurat)) %>%
distinct(cell_id, .keep_all = TRUE)
metadata <- metadata[match(colnames(ref_seurat), metadata$cell_id), ]
ref_seurat <- AddMetaData(ref_seurat, metadata = metadata$cell_type, col.name = "cell_type")
ref_seurat$cell_type <- factor(ref_seurat$cell_type)
ref_seurat <- NormalizeData(ref_seurat)
ref_seurat <- FindVariableFeatures(ref_seurat)
ref_seurat <- ScaleData(ref_seurat)
ref_seurat <- RunPCA(ref_seurat)
ref_seurat <- RunUMAP(ref_seurat, dims = 1:20)
query <- readRDS("/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/03_Clustered.rds")
query <- NormalizeData(query)
query <- FindVariableFeatures(query)
query <- ScaleData(query)
query <- RunPCA(query)
anchors <- FindTransferAnchors(reference = ref_seurat, query = query, dims = 1:20)
predictions <- TransferData(
anchorset = anchors,
refdata = ref_seurat$cell_type,
dims = 1:20
)
query[["predicted.id"]] <- predictions$predicted.id
query[["prediction.score.max"]] <- predictions$prediction.score.max
Idents(query) <- as.character(query$predicted.id)
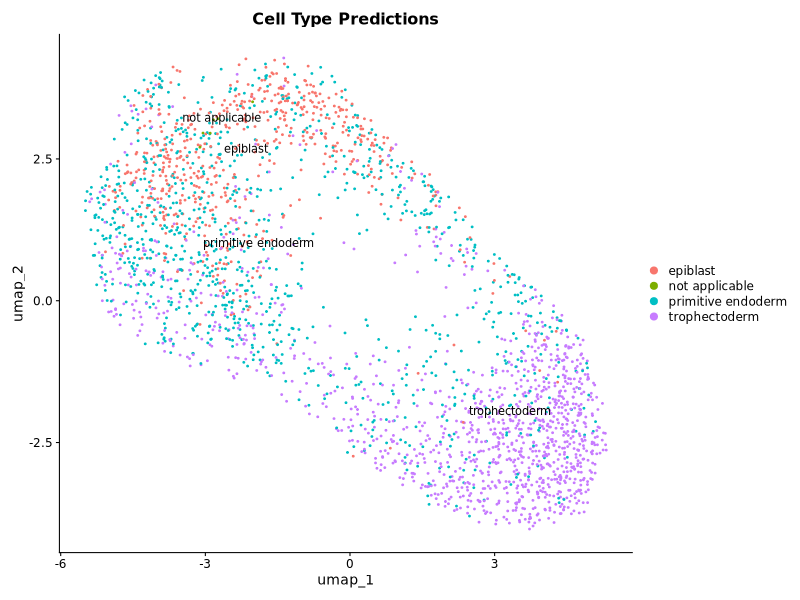
p1 <- DimPlot(query, label = TRUE, repel = TRUE, group.by = "predicted.id") +
ggplot2::ggtitle("Cell Type Predictions")
p2 <- VlnPlot(query) +
ggplot2::ggtitle("Prediction Confidence Scores")
png("AtlasLabelsHescUmap.png", width = 800, height = 600)
print(p1)
dev.off()
png("ViolinPredictionScores.png", width = 800, height = 600)
print(p2)
dev.off()
print(table(query$predicted.id))
```
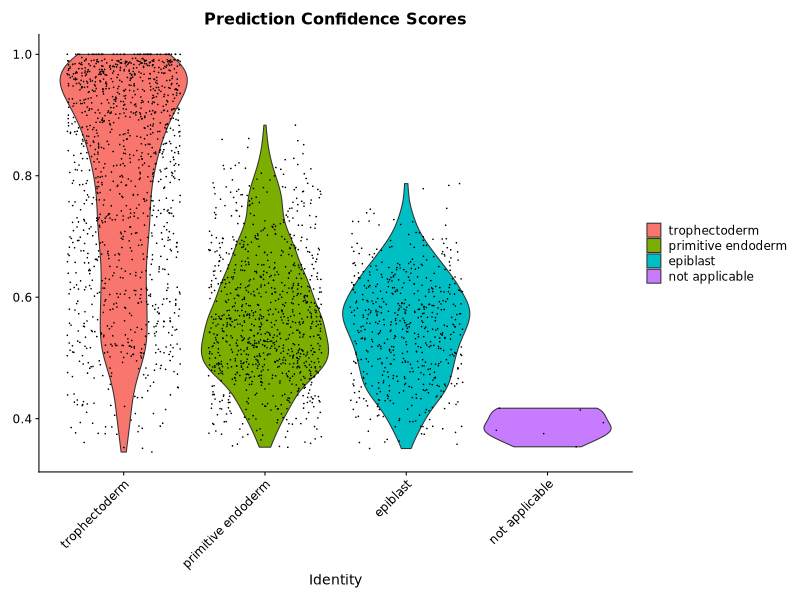
### Add reference labels to umap plot using the correct reference dataset
Download the reference data
```bash
/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered
https://www.ebi.ac.uk/biostudies/ArrayExpress/studies/E-MTAB-15075?query=%20E-MTAB-15075
unzip E-MTAB-15075.zip
```
**Run seurat with the publications reference data to label the cells in our selected sample without filtering reads**
run seurat with new reference data
```R
library(Seurat)
library(dplyr)
ref_seurat <- readRDS("2025.01.13_CH_synNotch_seurat_object.RDS")
# Confirm what metadata column holds cell type labels
# Uncomment to explore:
# head(ref_seurat@meta.data)
# Replace "cell_type_column" with the correct column name for cell types
# For our sample it's "base_annotation"
ref_seurat$cell_type <- factor(ref_seurat$base_annotation)
# Optional: normalize/scale again only if not already done
ref_seurat <- NormalizeData(ref_seurat)
ref_seurat <- FindVariableFeatures(ref_seurat)
ref_seurat <- ScaleData(ref_seurat)
ref_seurat <- RunPCA(ref_seurat)
ref_seurat <- RunUMAP(ref_seurat, dims = 1:20)
# Load query object (your sample)
query <- readRDS("/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_out/Gene/filtered/03_Clustered.rds")
# Preprocess the query object
query <- NormalizeData(query)
query <- FindVariableFeatures(query)
query <- ScaleData(query)
query <- RunPCA(query)
# Find anchors and transfer labels
anchors <- FindTransferAnchors(reference = ref_seurat, query = query, dims = 1:20)
predictions <- TransferData(
anchorset = anchors,
refdata = ref_seurat$cell_type,
dims = 1:20
)
# Add predictions to query object
query[["predicted.id"]] <- predictions$predicted.id
query[["prediction.score.max"]] <- predictions$prediction.score.max
Idents(query) <- as.character(query$predicted.id)
# Plot results
p1 <- DimPlot(query, label = TRUE, repel = TRUE, group.by = "predicted.id") +
ggplot2::ggtitle("Cell Type Predictions")
p2 <- VlnPlot(query, features = "prediction.score.max") +
ggplot2::ggtitle("Prediction Confidence Scores")
# Save plots
png("AtlasLabelsHescUmap.png", width = 800, height = 600)
print(p1)
dev.off()
png("ViolinPredictionScores.png", width = 800, height = 600)
print(p2)
dev.off()
# Summary
print(table(query$predicted.id))
```
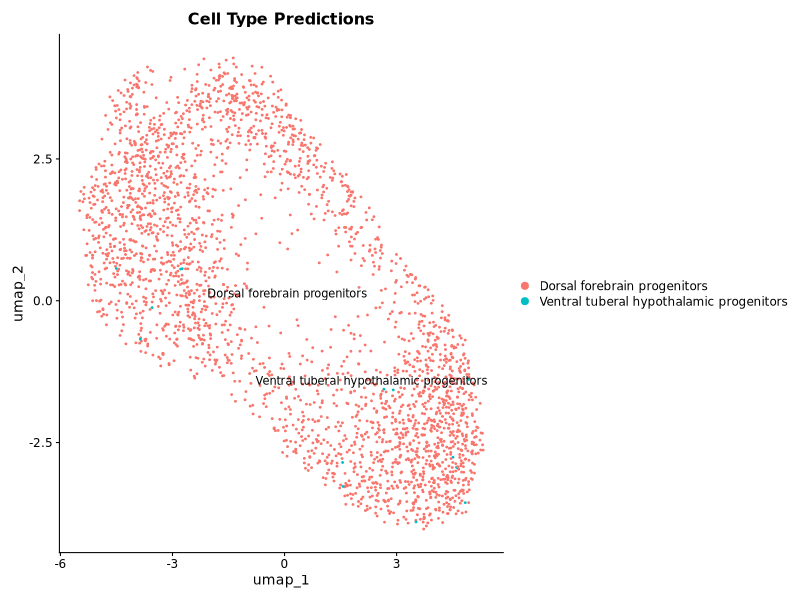
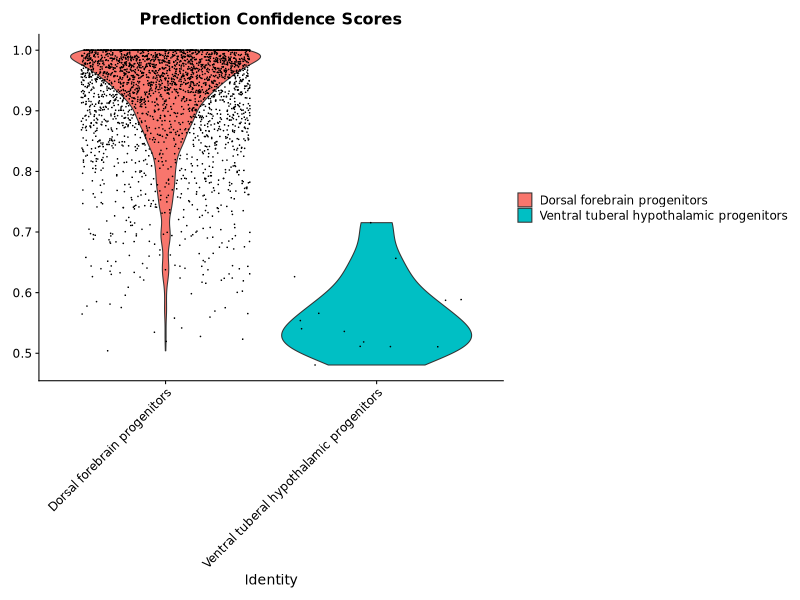
This worked, but the labels were not of very high confidence for the ventral tuberal hypothalamic progenitors.
### Run seurat with the publications reference data to label the cells in our selected sample using the filtered reads/alignments
```bash
/work/gif3/masonbrink/USDA/05_PipseqTutorial/02_AllRDSHesc_SHH
wget https://ftp.ebi.ac.uk/pub/databases/biostudies/E-MTAB-/075/E-MTAB-15075/Files/2025.01.13_CH_synNotch_seurat_object.RDS
```
Run seurat
```R
# Load libraries
library(Seurat)
library(dplyr)
library(ggplot2)
library(patchwork)
# Load the combined Seurat object
ref_seurat <- readRDS("/work/gif3/masonbrink/USDA/05_PipseqTutorial/02_AllRDSHesc_SHH/2025.01.13_CH_synNotch_seurat_object.RDS")
# Confirm what metadata column holds cell type labels
# Uncomment to explore:
# head(ref_seurat@meta.data)
# Replace "cell_type_column" with the correct column name for cell types
# Common column names might be: "cell_type", "CellType", "labels", or "predicted.id"
# For now, assuming it's "cell_type"
ref_seurat$cell_type <- factor(ref_seurat@meta.data$base_annotation)
# Optional: normalize/scale again only if not already done
# If the reference object is already normalized and embedded (check with `ref_seurat@reductions`),
# you may skip these steps:
ref_seurat <- NormalizeData(ref_seurat)
ref_seurat <- FindVariableFeatures(ref_seurat)
ref_seurat <- ScaleData(ref_seurat)
ref_seurat <- RunPCA(ref_seurat)
ref_seurat <- RunUMAP(ref_seurat, dims = 1:20)
# Load query object (your sample)
query <- readRDS("/work/gif3/masonbrink/USDA/05_PipseqTutorial/ERR14876813_Trim_Whitelist_out/Gene/filtered/03_Clustered.rds")
# Preprocess the query object
query <- NormalizeData(query)
query <- FindVariableFeatures(query)
query <- ScaleData(query)
query <- RunPCA(query)
# Find anchors and transfer labels
anchors <- FindTransferAnchors(reference = ref_seurat, query = query, dims = 1:20)
predictions <- TransferData(
anchorset = anchors,
refdata = ref_seurat$cell_type,
dims = 1:20
)
# Add predictions to query object
query[["predicted.id"]] <- predictions$predicted.id
query[["prediction.score.max"]] <- predictions$prediction.score.max
Idents(query) <- as.character(query$predicted.id)
# Plot results
p1 <- DimPlot(query, label = TRUE, repel = TRUE, group.by = "predicted.id") +
ggplot2::ggtitle("Cell Type Predictions")
p2 <- VlnPlot(query, features = "prediction.score.max") +
ggplot2::ggtitle("Prediction Confidence Scores")
# Save plots
png("AtlasLabelsHescUmap.png", width = 800, height = 600)
print(p1)
dev.off()
png("ViolinPredictionScores.png", width = 800, height = 600)
print(p2)
dev.off()
# Summary
print(table(query$predicted.id))
```
### Run the reference plot for the cells in the experiment's .rds file labeled by cell type
```R
library(Seurat)
library(ggplot2)
library(patchwork)
ref_seurat <- readRDS("/work/gif3/masonbrink/USDA/05_PipseqTutorial/02_AllRDSHesc_SHH/2025.01.13_CH_synNotch_seurat_object.RDS")
head(colnames(ref_seurat@meta.data))
[1] "orig.ident" "nCount_RNA" "nFeature_RNA" "sample_type"
[5] "plotting_ident" "RNA_snn_res.1.5"
Idents(ref_seurat) <- "plotting_ident"
# UMAP colored by cluster
p1 <- DimPlot(ref_seurat, group.by = "plotting_ident", label = TRUE) +
ggtitle("Clusters (plotting_ident)")
print(p1)
# UMAP colored by sample type
p2 <- DimPlot(ref_seurat, group.by = "base_annotation", label = TRUE) +
ggtitle("Sample Type")
print(p2)
#Expression of these genes on umap
p3 <- FeaturePlot(ref_seurat, features = c("SHH", "GLI1", "PTCH1"))
print(p3)
png("ExpressionByCluster.png", width = 800, height = 600)
print(p3)
dev.off()
png("UMAP_Clusters_only_rds.png", width = 800, height = 600)
print(p1)
dev.off()
png("UMAP_SampleType_only_rds.png", width = 800, height = 600)
print(p2)
dev.off()